-
What do neural networks learn in image classification? A frequency shortcut perspectiveAI/Analysis 2024. 4. 3. 11:57
ICCV 2023
What do neural networks learn in image classification?
A frequency shortcut perspective
해당 논문은 기존의 deep learning model 은 classification에서 어떻게 분류를 학습하는가? 에 대한 분석을 하고 있다.
Frequency의 관점에서 분석을 진행하여 기존 학습 방법에 대한 문제점을 제시하는 것이 매우 흥미롭다.
Doi: https://doi.org/10.48550/arXiv.2307.09829
What do neural networks learn in image classification? A frequency shortcut perspective
Frequency analysis is useful for understanding the mechanisms of representation learning in neural networks (NNs). Most research in this area focuses on the learning dynamics of NNs for regression tasks, while little for classification. This study empirica
arxiv.org
1. DNN

https://blog.ml.cmu.edu/2019/05/17/explaining-a-black-box-using-deep-variational-information-bottleneck-approach/ 기존의 DNN은 medical data analysis, self-driving vehicles, robotics, and surveillance 등과 같은 다양한 분야에서 사양되고 있다.
그러나, DNN은 prediction process가 non-linear multilayer strucrue의 block-box 특성으로 인해 완전히 이해하기에는 어려움이 있다.
DNN을 통해, 모든 함수를 근사화할 수 있지만, 수억개의 parameters로 인해 함수 근사화 프로세스에 대한 이해는 제한된다.
2. Analyzing the learned features
그래서 이를 이해하기 위한 다양한 연구들이 진행되었다.

1. https://kyujinpy.tistory.com/58 2. https://ai.atsit.in/posts/7588458119/ 3. https://praveenkumar2909.medium.com/overview-of-explainable-ai-and-layer-wise-relevance-propagation-lrp-cb2d008fec57 위와 같은 분석 방법은 input 측면에서 NNs의 예측을 설명하는 작업이다. 이를 통해, 예측에 기여하는 이미지의 영역을 강조하지만, OOD dataset에서 NNs의 성능이 저하되는 이유를 설명하지 못한다는 문제점을 가지고 있다.
3. Frequency perspective
Input 측면에서의 분석의 문제점을 개선하기 위해서 많이 연구된 다른 방법이 frequency의 관점에서 분석을 진행하는 것이다. Frequency domain의 측면에서의 분석 연구를 통해 regression task에서 NNs가 lower-frequencies를 먼저 학습하는 것으로 밝혀졌다. 이는 신호를 재구성하는데 필요한 대부분의 정보를 lower-frequencies에서 포함하기 때문이다.
이러한 bias learning behavior는 "simplicity bias"로 알려져 있다.
Simplicity bias는 문제와 관련된 의미보다는 최적화 작업을 더 단순하게 해결할 수 있는 단순하지만 효과적인 패턴, 즉 shortcuts를 NNs가 학습하다록 유도한다.

Frequency shortcut을 filter로 만들어서 적용하여, 주요 frequency 정보만 남긴 결과 Simplicity-bias learning 은 NNs에서 frequency-bias learning으로 이어지며, NNs가 예측을 용이하게 하는 특정 freqeucny, frequency shortcut을 사용하게 된다.
위, 그림은 freqeuncy shortcut이 적용되는 주요 frequency를 filter로 만들어, 주요 frequency만 남기는 것이다.
그림에서 오른쪽에 있는 이미지는 사람이 보았을 때, 구분을 하기 어려울 정도의 형체만을 가지고 있지만, frequenc shortcut이 적용되어 학습된 모델은 이를 구별할 수 있게 된다.
이는 class가 가지는 shape은 거의 무시되어 학습이 되었음을 의미하며 이러한 학습은 모델의 일반화 성능에 문제를 야기하게 된다.
기존 regression task와 차이는 classificiation 은 lower-frequencies 뿐만 아닌 다양한 주파수 편향을 보일 수 있다는 것이다.
4. Frequency shortcuts in image classification
앞서 얘기하였듯, regression task는 low-freqeuncy components (LFCs)를 우선 학습하는 경향이 있다.
하지만, 아직 classificaton에서는 이가 검증되지 않았다. 그러므로, 본 논문에서 저자들은 이를 실험하고 분석하고자 한다.
총 2가지 dataset을 이용하여 저자들은 분석을 진행하였다.

- Synthetic image: NNs의 learning behavior 연구, frequency domain 에서 shortcut을 발견하는 경향을 보인다.
- Nature image: synthetic data에서 얻은 insight를 바탕으로 frequency dependency 검사를 위한 frequency 제거에 기반한 방법을 제안한다.
5. Experiments on synthetic data
[ 5-1. Design of synthetic datasets ]

NNs의 learning behavior에 대한 다양한 frequency-bias 영향 검토를 위해 frequency band를 B1, B2, B3, and B4로 나눈다.
Band Frequency band B1 lowest frequency band B2, B3 mid-frequency band B4 highest frequency band If dataset of Syn_b 에서 b = B1일 때,
(CO, C1) -> band {B2, B3, B4}로 구성
C3 -> band B1으로 구성
이때, C0는 특정 이미지의 pattern을 포함하며 해당 pattern은 다른 class image에서는 제거된다.
이 pattern은 각 class에 대해 다른 수준의 데이터 복잡성을 포함하게 해 준다.
이로 인해 다양한 수준의 분류 난이도를 부여할 수 있게 된다.
b = B1 이외에 다른 경우는 아래의 table과 같다.


[ 5-2. Hypothesis ]
가설: NNs가 classification에서 가장 구별력 있는 frequency 특성을 가진 class를 구분하는 학습을 우선시한다.
NNs는 가장 단순한 방식으로 목표에 달성하려는 경향이 있으며, 이 결과로 regression에선 HFCs에 비해 LFCs를 먼저 근사하게 된다. 이러한 내용을 바탕으로 위의 가설을 저자들은 세우게 된다.
이 가설을 통해 NNs가 처음 배우는 것은 LFCs에만 한정되지 않고, data bias에 따라서 달라질 수 있다.
NNs는 더 단순한 방법으로 목표를 달성하기 위해 특정 frequency에 집중할 수 있기 때문에, 이는 frequency shortcut learning으로 이어질 수 있다.
[ 5-3. Data characteristics influence what NNs learn first ]
실험을 위해 ResNet-18을 기본 모델로 하여 학습을 진행하였다.
ResNet-18을 통해 저자들은 다른 class 보다 뚜렷한 특성을 가진 C0와 C3와 같은 class를 초기 단계에서 쉽게 구별할 수 있기를 기대하였다.
이를 실험하기 위해, 첫 500 iteration에서 class 별 F-1 score를 측정하였다.

초기 iteration 에서의 F1-score 위 그림을 통해 C3가 다른 class 보다 일반적으로 F1-score가 더 높음을 확인할 수 있으며, 이어서 두 번째로 C0가 높음을 확인할 수 있다.
이는 C3가 네 개의 synthetic dataset 전반에서 다른 class들과 즉시 구별되는 특징을 가지고 있음을 나타내며, class C3의 구별 가능한 특성이 NNs의 learning behavior를 주도하는데 중요한 역할을 한다는 것을 시사하고 있다.
4개의 synthetic dataset에 걸친 다양한 대역의 bias에도 불구하고, 항상 class C3가 먼저 학습된다.
이는 훈련 초기에 다른 frequency 보다 더 구별력이 있다면 NNs가 low-frequency 나 high-frequency를 배울 수 있음을 시사한다.
따라서, classificiation에서 NNs가 먼저 배우는 frequency는 simplicity-bias and data characteristics에 의해서 주도된다.
[ 5-4. Data bias and simplicity bias can lead to frequency shortcuts ]
Synthetic data과 frequency 특성을 기반으로, 원본 synthetic data와 B의 두 band가 제거된 band-stop version에서 테스트한 NNs의 분류 결과를 비교한다. 비교할 때, 아래의 수식을 통해 score를 구하였다.

∆^(C_i, C_j이는 limited bands가 classification을 위한 충분한 구별 정보를 제공한다는 것을 의미한다. 또한 결과 값이 음수 값일 때는 성능이 떨어짐을 나타낸다.
네 개의 synthetic datasets에서 class C2는 모든 band의 frequency를 포함하도록 설계되었다.
모델이 학습에서 전체 spectrum에 걸친 frequency를 고려하는 대신, 부분 대역의 frequency 만을 가지고 class C2를 예측할 수 있다면, 그 모델은 class C2를 예측하기 위해 frequency shortcuts를 사용한 것으로 간주할 수 있다.

위 그림을 통해 SynB1, SynB4에서 훈련된 모델에 대한 ∆^(C_2, C_2
NNs가 C2의 sample을 분류하기 위해서 제한된 band에서 frequency shortcuts을 적용한다는 것을 위 결과를 통해 확인할 수 있다.
6. Experiments on nature images
[ 6-1. A frequency distribution comparsion metric ]
NNs가 배우는 것을 종합적으로 이해하기 위해서, dataset 내 개별 class의 frequency 특성을 검사하는 것은 중요하다.
NNs가 amplitude-dependent 하다는 점을 고려하여, accumulative difference of class-wise average spectrum (ADCS)를 본 저자들은 제안하였다.

각 class 내의 average amplitude spectrum 차이를 채널별로 계산하고, 이를 하나의 채널 ADCS로 평균화한다.
높은 값은 특정 class가 다른 class에 비해 특정 frequency에서 더 많은 energe를 가짐을 나타낸다.
[ 6-2. Impact of class-wise frequency distribution on the learning process of NNs ]
ImageNet-10을 사용하여 학습을 진행하였다.
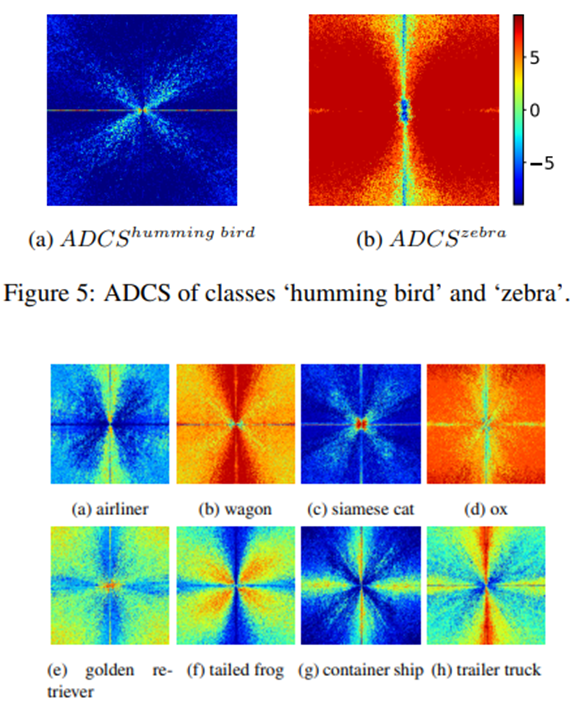
각 class별 ADCS를 시각화한 결과 위 그림의 ADCS를 통해 "humming bird"와 "zebra" class가 초기 학습 단계에서 다른 class와 구분하는데 모델이 쉽게 활용할 수 있는 독특한 frequency를 가짐을 확인할 수 있다.
Humming bird는 평균적으로 거의 전체에 걸쳐 다른 class보다 훨씬 더 적은 energe를 가짐을 확인할 수 있으며, Zebra는 mid and high frequency에서 뚜렷한 energy 우위가 있다.
이러한 frequency 특성이 학습에 미치는 영향을 검증하기 위해, NNs를 ImageNet-10으로 학습하고 원래 testset이 아닌 high frequency and low frequency version의 testset을 만들어 test를 진행하였다.

testing 결과 위 그림을 통해, precision과 recall이 "zebra" class precision과 "humming bird" class recall이 일반적으로 다른 class보다 높음을 확인할 수 있다.
이는 이 두 class가 다른 class에 비해 빠르게 학습됨을 나타낸다.
분류를 위한 NNs가 초기 학습 단계에서 매우 구별력 있는 특성으로 class 간의 상당한 spectrum 차이를 학습에 활용할 수 있음을 나타낸다. 이는 NNs가 처음 배우는 것은 frequency 특성에 의해 영향을 받는다는 이전 section에서의 synthetic data를 활용한 연구를 통해 발견을 서포트한다.
[ 6-3. A frequency shortcut identification method ]
이전 실험과 같이 nature image에서 관련 없는 frequency를 제거하는 방법을 저자들은 제안한다.
모든 channel에서 해당 frequency 를 제거한 특정 class의 이미지에서 모델을 test 할 때, 손실값을 측정하여 각 frequency와 분류의 관련성을 측정하였다.
손실값의 증가는 frequency의 중요성을 메기는 지표가 된다.

Dominant Frequency Map (DFM) 더 높은 손실값을 가진 frequency들은 주어진 순위에 따라 top-X% frequency를 선택함으로써 특정 class의 dominant frequency map (DFM)이 된다.
이렇게 얻은 DFM을 사용하여, dominant frequency가 image classification에 미치는 영향과 그것들이 특정 class에 대한 편향된 예측으로 이어지는 frequency shortcut을 어느 정도 나타내는지를 확인할 수 있다.
이를 정량화하기 위해서 testset의 모든 이미지가 특정 class의 top-X% frequency만을 유지하도록 한다.
각 class에 대한 discrimination power와 specificity를 평가하기 위해서 TPR과 FPR을 계산한다.
높은 TPR과 FPR을 가진 class는 classifier가 frequency shortcut을 학습하고 적용하도록 유도된 사례로 간주한다.

[ 6-4. Frequency shortcuts can be texture- or shape-based ]

ResNet18로 학습을 하였을 때, class zebra와 container ship의 TPR과 FPR이 다른 class에 비해서 높음을 확인할 수 있으며, 이는 두 class에 대해서 frequency shortcut이 적용되고 있다는 것을 나타낸다.

ResNet18과 shape information을 강조하기 위해 객체 texture를 대체하는 SIN을 사용하여 훈련된 경우 "siamese cat"의 frequency shortcut을 학습함을 확인할 수 있다.

DFM 적용 이미지 위의 그림은 위 표에서의 "container ship"과 "siamese cat"의 이미지의 해당 DFM만 유지하는 이미지의 예이다.
해당 이미지는 사람이 이미지를 분류할 수 없는 상태지만, NNs는 frequency shortcut으로 인해 이를 분류할 수 있다.
이는 이미지의 shape 보다는 texture에 초점이 맞춰진 frequency shortcut이 적용되었음을 의미하며, 이렇게 학습된 frequency shortcut은 NNs의 의미론을 학습하는 것을 방해할 수 있다.

texture based 위의 그림을 보면, 얼룩말 옷을 입은 사람이 높은 confidence를 가지고 "zebra"로 예측되며, "ox"는 낮은 confidence를 가짐을 확인할 수 있다. 하지만 이는 얼룩말의 무늬를 가진 옷이지 얼룩말은 아니다.
이러한 분류결과는 모델이 얼룩말의 형태 정보를 거의 다 무시하고 texture pattern 만 이용한다는 증거이다.
"zebra" class는 훈련 초기에 쉽게 인식되며, 이는 학습된 frequency shortcut이 동물의 형태와 같은 다른 중요한 의미론 학습을 방해했다고 확인할 수 있다고 한다.
이러한 frequency shortcut은 모델의 일반화 성능에 저해를 가져오게 된다.
[ 6-5. Model capacity vs. frequency shortcuts ]

ResNet50의 high TPR and FPR은 "airliner"와 "container ship"이다. 해당 두 class에 frequency shortcut이 적용되었다.
ResNet50은 ResNet18에 비해 "zebra"에 대해서는 더 낮은 TPR과 FPR를 가지며, 이는 "zebra" 분류에 대해 덜 특징적인 dominant frequency를 가짐을 의미한다.
VGG16의 high TPR and FPR은 "container ship"임을 확인할 수 있다.

또한 CNN 기반의 model 뿐만 아닌 ViT에서도 frequency shortcut이 "simese cat"과 "container ship"에서 적용되었음을 확인할 수 있다.
다양한 model capacity와 아키텍처를 가진 모델에도 frequency shortcut은 영향을 미침을 확인할 수 있다. 그러므로, 더 큰 모델이 반드시 frequency shortcut을 피할 수 있는 것은 아니다.
이러한 실험의 결과는 frequency shortcut은 data-driven 하다는 것을 보여주며, 일반화 가능한 모델을 학습하기 위해서는 보다 이를 명확히 고려해야 한다.
[ 6-6. Transferability of frequency shortcuts ]

일반적으로 일반화 성능을 올리기 위해 많이 채택되는 방법은 augmentation이다.
해당 section에서는 그렇다면 augmentation은 frequency shortcut learning 완화에도 효과가 있는지 확인해 본다.
AugMix의 경우 "container ship"에서는 악화되지만, "zebra"에서는 완화되었음을 확인할 수 있다.
AutoAug의 경우는 "zebra"와 "container ship" 모두에서 frequency shortcut을 부분적으로 피했음을 확인할 수 있다.
SIN의 경우는 "siamese cat"에서 frequency shortcut이 발생함을 확인할 수 있다.
이를 통해 적절한 augmentation은 frequency shortcut을 부분적으로 줄일 수는 있지만, NNs는 여전히 augmentation 된 data 특성에서 기반한 shortcut 해결책을 찾는 경향이 있음을 확인할 수 있다.
[ 6-7. 추가적인 실험 결과 ]




7. Summary
1) Classification에 대해서는, NNs가 데이터 특성 때문에 simplicity bias learning을 통한 frequency shortcut을 채택하고 적용되는 경향이 있다. 이때, regression task와 달리 다양한 frequency 대역에서 편향을 보일 수 있다.
2) Model capacity 가 크거나 augmentation을 적용하면 부분적으로 frequency shortcut을 피할 수는 있지만, 완전히 이를 피하여 문제를 해결할 수 있는 것은 아니다.
3) 일반화 성능 개선을 위해서는 고려해야 하는 문제이다.
'AI > Analysis' 카테고리의 다른 글
Resonsible AI - Studying Bias in GANs through the Lens of Race (0) 2025.03.28 AI models collapse when trained on recursively generated data (0) 2024.08.27