-
NIPS 2018
Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks
Ali Shafahi, W. Ronny Huang, Mahyar Najibi,
Octavian Suciu, Christoph Studer, Tudor Dumitras, Tom Goldstein
해당 논문은 Poisoning Attack에 관한 논문으로 하나의 Poison Instance를 이용해서 Network 전체를 감염시킬 수 있는 방법에 대한 논문이다.
Deep Neural Network(DNN) Model을 만들면서 우리가 쉽게 간과하던 보안적인 문제에 대해서 다시 한번 생각하게 만드는 논문이며 내용이 재미있어서 읽어 보았다.
DOI : https://doi.org/10.48550/arXiv.1804.00792
Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks
Data poisoning is an attack on machine learning models wherein the attacker adds examples to the training set to manipulate the behavior of the model at test time. This paper explores poisoning attacks on neural nets. The proposed attacks use "clean-labels
arxiv.org
1. Introduction
Deep learning algorithm은 보안이 중요한 application에 배포되기 전에 공격에 대한 견고성을 확인해야 한다. DNN의 적대적 예시(Adversarial Example)하여 clssifier의 안정성에 혼란을 야기할 수 있기 때문이다.

evasion attack Adversarial Example은 분류를 하자면 evasion attack(회피 공격)의 범주에 속한다.
Evasion attack 은 test시에 발생하는 공격으로 clean target instance가 classifier의 detection을 피하거나 오분류를 일으키도록 modified 된다.
하지만 해당 시나리오는 현실적이지 않다. 공격자가 test시에 data를 제어할 수 없기 때문에 clean target instance를 test시에 변경이 불가능하기 때문이다.
예를 들어 ML기반 spam filter를 통해 경쟁 업체에 e-mail을 spam으로 표시한다고 생각해 보자.
이때 공격자가 피해자의 e-mail을 수정할 수 없기 때문에 evasion attack은 적용될 수 없을 것이다.
비슷하게, 적은 직원이 상주하는 보안 데스크나 건물 입구와 같이 감독되는 조건에서 작동되는 face recognition engine의 input을 변경하지 못할 것이다.
이 와같이 중간에 공격자는 피해자의 시스템에 개입할 수 없기 때문에 이는 비현실적인 공격 방법이다.
하지만 이러한 시스템은 여전히 "Data Poisoning attack"에 취약하다.
Data Poisoning Attack은 신중하고 정교하게 구성된 poison instance를 training data에 삽입하여 system 성능을 조작하는 것을 목표로 한다.
본 논문은 target neural net에 대한 poisoning attack을 연구한 논문으로 하나의 specific test instance에서 classifier의 동작을 제어하는 것을 목표로 하며 이들은 labeling function을 제어할 필요가 없는 clean label attack을 제안한다.
이로 인해 공격탐지가 어려우며, 공격자가 data 수집 및 labeling에 대한 process에 내부 access 없이 공격을 성공할 수 있다.

Poisoning attack 예시 이들이 제안하는 공격방법을 진행하는 방법을 생각해 보자.
우리는 데이터를 모으고 network의 학습을 진행하기 위해서 crawling을 통해 데이터를 모으는 경우가 많다.
이 점을 이용해서 저자들은 poison attack 할 수 있다고 한다.
우선 공격자가 중독된 이미지를 온라인에 배치한다. 그리고 이 중독된 이미지를 crawler가 스크랩할 때까지 기다린다. 이 데이터는 사람이 보기에는 큰 문제가 없는 이미지이기 때문에 일반 이미지들과 동일하게 labeling을 할 것이고 학습을 진행하게 될 것이다. 그럼 이 이미지가 network의 backdoor가 되어 test시에 공격자는 network에 공격이 가능해진다.
2. A simple clearn-label attack
이들은 test시에 classifier의 동작을 조작하는 poison instance를 만들기 위한 optimization-based procedure를 제안한다.
그 후 이 간단한 공격의 위력을 높이는 방법에 대해서 설명할 것이라고 한다.
Optimization-based procedure는 아래와 같다.
1) 공격자는 test set에서 target instance를 선택한다.
2) base class에서 base instance를 sampling 하고 눈에 띄지 않게 변경하여 poison instacne를 만든다.
3) model은 poisoning 된 dataset을 학습한다.
--> 테스트 시 model이 이 instance를 base class에 있는 것으로 착각하면 poisoning attack이 성공한 것으로 간주한다.
2.1 Crafting poison data via feature collisions
함수 f(x)는 input x를 끝에서 두 번째 layer (before softmax layer)로 propagates 하는 함수를 나타낸다.
이들은 해당 layer의 activation을 input의 feature space representation이라고 부른다. 이렇게 부르는 이유는 high-level semantic features를 encoding 하기 때문이라고 한다.
f의 high complexity와 nonlinearity 때문에 x가 feature space에서 target과 충동하면서 동시에 연산에 의해 inputt space에서 base instance b에 근접하는 예를 찾을 수 있다고 한다. 이를 수식으로 표현하면 아래와 같다.

제안하는 방법 수식 (1) 위 수식 (1)을 오른쪽과 왼쪽 항으로 나누어서 확인해 보자.

수식 (1)의 오른쪽 항 오른쪽 항은 poison instance p가 인간 labeler에게 base class instance처럼 나타나도록 한다. ( β는 이것이 어느 정도인지를 매개변수 화한 것이다.)

수식 (1)의 왼쪽 항 왼쪽 항은 poison instance가 feature space에서 target instace로 이동하고 target class distribution에 포함되도록 하는 항이다. 이 부분을 통해서 수식을 통해 clean model에서 이 poison instance는 target으로 잘못 분류된다.

모델이 clean data + poison instance에서 retrain 되는 경우 feature space의 linear decision boundary가 위 그림과 같이 rotate 되어 마치 base class에 있는 것처럼 poison instance의 label을 지정할 것으로 예상된 다고 한다. target instance가 근처에 있기 때문에 decision boundary rotation은 실수로 poison instacne와 함께 base class의 target instance를 포함할 수 있다.
이를 통해 test시에 base class로 잘못 분류되는 교란되지 않은 target instance가 base class의 "backdoor"를 얻을 수 있다.
2.2 Optimization procedure
p를 얻기 위해 위 수식 (1)에서 최적화를 수행하기 위한 이들의 procedure는 아래의 알고리즘 1에 나와 있다.

알고리즘은 forward-backward-splitting iterative procedure를 사용한다.
첫 번째 forward step 은 feature space에서 단순히 target instance까지의 L2 distnace를 minimize 하기 위한 gradient descent update이다.
두 번째 backward step 은 input space에서 base instace로부터 Frobenius distance를 minimize 하는 proximal update이다.
계수 β 는 poison instance가 input space에서 사실적으로 보이도록 조정되어 순진한 인간 관찰자가 attack vector image가 변조되지 않았다고 생각하도록 속일 수 있게 한다.
3. Poisoning attacks on transfer learning
이제 이들이 진행한 중독 실험에 대해서 알아보자.
이들은 pre-trained feature extraction network를 사용하고 최종 softmax layer만 특정 task에 맞게 network를 조정하도록 훈련되는 transfer learning의 경우를 확인하는 것으로 시작한다.
해당 transfer learning 기법은 실제로 제한된 data에 대해서 강한 classifier를 얻기 위해 많이 사용되는 방법이다.
이 경우에 poisoning attack은 매우 효과적일 것이라고 한다.
이들은 두 가지 중독 실험을 진행하였다.
먼저 마지막 layer를 제외한 모든 layer의 weight가 고정된 시나리오에서 사전 훈련된 InceptionV3 network를 공격한다.
둘째, 이들은 모든 layer가 훈련되는 시나리오에서 CIFAR-10 dataset용으로 수정한 AlexNet architecture를 공격한다.
3.1 A one-shot kill attack
이제 이들은 transfer learning network에 대한 간단한 poisoning attack을 제시한다.
이 경우에는 "one-shot kill attack"이 가능하다.
Training set에 하나의 poison instance만 추가하면 100% 성공률로 target을 잘못 분류할 수 있다고 한다.
InceptionV3을 feature extractor로 기본적으로 활용하고 개와 물고기를 분류하기 위해 최종 fully-connected layer weight를 재교육한다. ImageNet의 각 class에서 900개의 instance를 train data로 선택하고 preprocessing step을 통해 train data에 있는 test data에서 중복을 제거한다.
그 후 1099개의 test instance (dog class : 698개, fish class : 401개의 test instance)가 남는다.
Test set에서 target instance와 base instance를 모두 선택하고 maxIters = 1000인 알고리즘(1)을 사용하여 poison instance를 만든다. ImageNet의 image는 dimensions가 다르기 때문에 β를 계산한다.
β는 다음과 같은 수식에 따라 계산이 된다.

해당 수식을 통해 base instance(dim_b)의 dimension과 InceptionV3의 feature space representation layer를 고려한다.
β_0 = 0.25의 값을 사용하였다.
그런 다음 train data에 poison instacne를 추가하고 cold-start training을 수행한다.
이 실험을 통해 각각 다른 test set image를 target instance로 사용하여 1099회 수행되어 공격 성공률이 100%였다고 한다.

일반적으로 transfoer learning을 통해 100% 성공률을 얻는 것은 불가능하다.
Dog-vs-fish task에서 InceptionV3을 사용하여 이러한 성공률을 얻을 수 있는 이유는 trainig examples(1801)보다 trainable weights(2048)가 더 많기 때문이라고 한다.
데이터 metrix에 중복 이미지가 없는 한 weight vector를 찾기 위해 해결해야 하는 방정식 시스템은 충분히 결정되지 않았으며 모든 train data에 overfitting이 발생할 것이 확실하기 때문이다.

공격이 성공하는 원인을 더 잘 이해하기 위해 위의 그림은 2에서 clean network와 poisoning network의 decision boundary 사이(즉, weight vector 간의 각도 차이)의 각도 편차를 ploting 한 것을 확인해 보자.
각도 편차는 poison instance에 대한 재훈련으로 인해 base region내의 poison instacne를 포함하도록 decision boundary가 rotate 되는 정도이다. 이 편차는 위 그림 2 (b)에서 볼 수 있듯이 대부분 첫 번째 epoch에서 발생하며 suboptimal hyper parameter로도 공격이 성공할 수 있음을 시사한다. 평균 23도의 최종 편차는 poison instance에 의해 최종 layer decision boundary가 크게 변경되었음을 나타낸다. 이러한 결과는 decision boundary의 변화로 인해 target의 오분류가 발생하다는 이들의 직관을 확인할 수 있다.
해당 실험은 binary classification task("dog" vs "fish")에 관한 것이다. 그러나 많은 class 문제에 동일한 poisoning procedure를 적용하는데 제약이 없다. 이들은 새로운 class인 "cat"을 도입하고 clean-test image에서 96.4%의 정확도를 유지하면서 3-way task에서 100% poisoning 성공을 보여주는 추가실험을 진행하여 확인하였다.
(논문의 Supplementary Materiall 확인)
4. Poisoning attacks on end-to-end training
위의 section 3에서 transfer learning에 대한 poisoning attack이 매우 효과적이라는 것을 확인했다. 하지만 모든 layer가 훈련 가능하면 이러한 공격이 더 어려워진다. 이는 "water marking" trick과 여러 poison instance를 사용하면 end-to-end network를 효과적으로 poisoning 할 수 있다고 한다.
이번 이들의 end-to-end 실험은 CIFAR-10 dataset에 대한 축소된 AlexNet architecture에 초점을 맞추고, pre-trained weight로 초기화(warm-start)되며 learning rate 1.85 x 10^-5에서 Adam으로 optimization 되었다.
batch size가 128이며 10 epoch 이상 학습을 진행하였으며 warm start로 인해 network가 poison instance를 올바르게 분류하도록 readjusted 된 후 마지막 몇 epoch 동안 loss가 일정함을 확인했다고 한다.
4.1 Single poison instance attack
이들의 목표는 network의 동작에 대한 poison의 영향을 visualize 하고 end-to-end training에서 posioning attack이 transfer learning보다 더 어려운 이유를 설명하는 것이다.
본 논문의 저자들은 실험을 위해 random으로 "airplanes"를 target class로, "frog"를 base class로 선택하였다.
poison instacne 제작을 위해서 β = 0.1과 iteration을 12000으로 사용하였다.

그림 3 (a) 위 그림 3(a)은 193-dimension의 deep feature vector를 2-dimension 평면에 투영하여 visualize 된 target, base 및 poison feature space representation을 보여준다.
첫 번째 dimension은 base class와 target class의 중심을 연결하는 vector인 u :

를 따르는 반면, 두 번째 dimension은 u에 직교하는 vector를 따라 u와 θ에 걸쳐 있는 평면에 있다. 이는 penultimate layer의 weight vector, 즉 decision boundary에 대한 법 선을 의미한다고 한다.
이 projection을 통해 두 class(target and base)의 분리를 가장 잘 나타내는 관점에서 data distribution을 visualize 할 수 있다고 한다.
그런 다음 이들은 clean data + single poison instance로 model을 교육하여 poisoning attack을 평가하였다.
위 그림 3(a)은 clean(unfille dmarkers) model과 poisoned(filled markers) model에서 training data와 target, base 및 poison instance의 feature space representation을 보여준다.
Clean model feature space representation에서 target 및 poison instance가 중첩되어 이들이 제안하는 알고리즘(1)이 작동함을 나타낸다. 이상하게 base region 내 posion instance를 수용하기 위해 최종 layer decision boundary가 rotate 하는 transfer learning 시나리오와 달리, 위의 그림 2에서 볼 수 있듯이 end-to-end training 시나리오의 decision boundary는 빨간색으로 표시된 것처럼 poisoned dataset에 대한 재훈련 후에도 변경되지 않았음을 확인할 수 있었다고 한다.
즉, poison instance 생성은 poison intance가 feature space에서 target과 나란히 배치되도록 초기 layer의 feature extraction kernels의 불완정성을 이용한다.
Network가 이 poison instacne에서 재교육될 때, 기본으로 label이 지정되기 때문에 이러한 초기 layer feature kernel 결함이 수정되고 poison instacne가 base class로 반환되는 것!
내가 이해한 대로 쉽게 말하면, poison instace 때문에 발생하는 초기 layer feature kernel에서의 결함이 주어진 label에 맞춰 수정되어 base class로 그냥 반환된다는 의미 같다.
이 결과는 poison instacne 생성과 network training의 목표가 상호 대립하므로 single poison으로는 극단적인 이상치인 target example을 손상시키기엔 충분하지 않을 수 있다는 것을 의미한다.
공격이 성공하려면 재교육시에 target instance와 poison instacne가 feature space에서 분리되지 않도록 하는 방법을 찾아야 한다고 한다.
4.2 Watermarking: a method to boost the power of poison attacks
저자들은 training 중에 poison과 target이 분리를 방지하기 위해 간단하지만 효과적인 trick을 사용하였다.
Target instance의 low-optical watermark를 poison instance에 추가하여 시각적으로 뚜렷하게 유지하면서 분리할 수 없는 feature overlap을 허용한다. 이는 target instance의 일부 feature를 poison instance에 혼합하고 poison instace가 재훈련 후에도 target instance의 feature space에 근접하도록 유지할 수 있게 한다.
Watermarking은 다른 연구자들에게 제안되었지만, 이는 inference time 동안 watermark가 적용되어야 했다. 하지만 이것은 target instance를 제어할 수 없는 상황에서 비현실적이다.
Base b와 target image t 가 있다고 하였을 때 weighted combination을 하여 target opacity γ를 갖는 base watermarked image를 형성한다. 이를 수식으로 표현하면 아래와 같다.
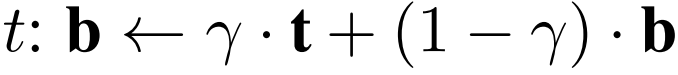
Watermark는 일부 target instance에 대해 최대 30% 불투명도까지 가지며 시각적으로 눈에 띄지 않는다.

위 그림은 "bird" target instance를 성공적으로 공격하는 데 사용되는 60개의 poison instacne를 나타낸다.
4.2.1 Multiple poison instance attacks
End-to-end training 시나리오에서 poisoning은 network가 target과 poison을 최적으로 구별하는 feature embedding을 학습하기 때문에 어렵다. 그러나 서로 다른 base instance에서 파생된 여러 poison instance를 training set에 도입하면 어떻게 될까?
이렇게 되면 classifier는 여러 poison에 저항하기 위해 target instance가 target distribution에 남아 있는지 확인하면서 모든 poison instance를 target에서 분리하는 feature embedding을 training 해야 된다.
결과적으로 network가 재훈련되면 target instance가 poison instance와 함께 base distribution 방향으로 당겨지게 되고 attack이 자주 성공한다고 한다. 이러한 결과는 아래의 그림을 통해서 확인할 수 있다.

그림 3 (b) 이전에 보았던 그림 2와 달리 multiple poison 실험에서도 최종 layer의 decision boundary가 변경되지 않고 남아 있음을 확인할 수 있고 이는 transfer learning과 end-to-end learning 시나리오에서 poisoning 이 성공하는 근본적으로 다른 메커니즘이 있음을 시사한다.
Transfer learning은 target을 포함하도록 decision boundary가 rotate 하여 poison에 반응하는 반면, end-to-end training은 target을 base distribution으로 끌어당겨 반응한다. 그렇기 때문에 end-to-end training 시나리오의 decision boundary를 poisoned dataset을 재학습하여도 고정된 상태로 유지된다.
Poison intance의 수가 성공률에 미치는 영향을 정량화하기 위해 1~70 (5씩 증가) 사이의 각 poison instance 수에 대해서 이들은 실험을 진행하였다. 실험은 test set에서 무작위로 선택된 target instance를 사용하였으며 poison은 test set의 random base에서 생성되었다. 30%~20%의 watermarking opacity를 사용하여 poison과 target 사이의 feature overlap을 향상했다고 한다.
공격 성공률은 아래의 그림에 나와 있다.

성공률은 poison instance의 수에 따라서 증가함을 확인할 수 있다. 50개의 poison으로 "bird-vs-dog"에서의 성공률은 약 60% 정도이다. target이 base로 분류된 경우만 성공으로 간주하고 확인한 점수라고 한다.
target instance가 base 이외의 class로 잘못 분류된 경우에는 공격이 실패한 것으로 간주된다.
데이터 이상값을 target으로 하여 이 공격의 성공률을 높일 수 있었다. 이러한 target은 해당 class의 다른 training sample과 멀리 떨어져 있으므로 class label을 뒤집기가 더 쉽다고 한다.
올바르게 분류되었지만 분류 신뢰도가 가장 낮은 50대의 "airpalne"을 대상으로 하고 공격당 50개의 poison frog를 사용하여 공격했을 때, 해당 공격의 성공률은 위 그림 5(a)에서 확인할 수 있듯이 70%이며 무작위로 선택한 targe보다 17%가 높다.
End-to-end 시나리오에서 clean label attack이 작동하기 위한 내용을 정리해 보면 아래와 같다.
1) 알고리즘(1) (이들이 제시한 방법)을 통한 최적화
2) poison instance의 다양성
3) watermarking 등 여러 기술의 필요
해당 논문은 우리가 DNN model을 설계하고 학습을 위한 데이터를 취득하기 위한 과정에서의 안정성에 대한 생각을 하게 하는 논문이었다.
이전에 인턴 보내며 데이터를 취득하고 modeling을 하는 직무를 하였었는데 수치 데이터이긴 했지만 그때도 crawling을 통해서 추가적인 데이터를 취득했기 때문이다.
개발자가 이런 식으로 온라인에서 취득하는 데이터의 신뢰성 및 출처에 대해서 관심을 가지고 이러한 사람의 눈으로 보이지 않는 위조 데이터에 대해서 어떻게 사전에 처리를 해야 할까?라는 고민을 항상 해야 된다고 생각한다.
하지만 본 논문에서는 해당 방법이 현실적이라고는 하지만 우리가 보통 model을 만들고 학습을 진행할 시에 학습에 사용하는 데이터를 늘려주기 위해서 augmentation을 적용하기 때문에 이들이 복제한 poison instance가 과연 변형 없이 온전하여 network를 공격할 수 있을까?라는 의문이 든다.
augmentation을 통해 데이터에 변형이 가해져 poison instance도 분명 공격자가 처음에 의도했던 방향과는 다른 형태가 될 것이기 때문이다.
현실적이다!라는 문제에서는 많은 의문이 들기는 하지만 해킹과 공격에 대해서는 분명히 우리가 항상 고민해야 될 문제일 것이다.
'AI > Vision' 카테고리의 다른 글
Vision Transformer (0) 2023.09.14 Kernel Aware Resampler (0) 2023.06.30 YOLOv3: An Incremental Improvement (0) 2023.06.01 Instant NGP : Instant Neural Graphics Primitives with a Multiresolution Hash Encoding (0) 2023.05.24 Self-attention does not need O(n^2) memory (0) 2023.05.23