-
Digital Gimbal : End-to-end Deep Image Stabilization with Learnable Exposure TimeAI/Vision 2022. 12. 13. 16:09
Digital Gimbal :
End-to-end Deep Image Stabilization with Learnable Exposure Times
Omer Dahary 1, Matan Jacoby 1, and Alex M.Bronstein 1
우리는 실생활에서 카메라로 움직이는 상황이나 움직이는 물체를 촬영하는 경우가 많다.
예를 들어 차량의 블랙박스는 달리는 차안에서 움직이거나 정지되어 있는 피사체들을 촬영하게 된다.
드론에 부착되어 조종자의 조작을 돕거나 영상 촬용을 위해서 부착되어 있는 카메라 또한 블랙박스와 동일한 피사체들을 촬영하게 될 것이다.
이때 촬용기기가 움직이거나 움직이는 피사체를 촬영하게 되면 motion blur라고 하는 잔상이 남게 되는데 이는 육안으로 이미지에서의 피사체를 구분하거나 원하는 사진을 촬영에 방해가 되기도 하면 segmenation 혹은 detection의 성능에도 영향을 미치게 된다.
이렇듯 위와 같은 경우 motion blur에 의해 고통을 받게 되고 이를 해결하기 위해서 deblurring 연구가 활발하게 진행되고 있다.
이번에 소개할 논문도 motion blur를 제거하기 위한 방법을 제안하는 논문이다.
CVPR에서 소개된 논문으로 접근 방법이 재미있는 논문이라 생각한다.
Paper doi : https://doi.org/10.48550/arXiv.2012.04515
Digital Gimbal: End-to-end Deep Image Stabilization with Learnable Exposure Times
Mechanical image stabilization using actuated gimbals enables capturing long-exposure shots without suffering from blur due to camera motion. These devices, however, are often physically cumbersome and expensive, limiting their widespread use. In this work
arxiv.org
1. Introduction
이미지 기술의 발전을 통해서 optical system은 가벼워지고 휴대성이 좋아졌다. 그러나 이러한 발전들은 핸드헬드 카메라의 떨림이나 카메라가 탑재된 차량의 움직으로인해 카메라가 움직이는 것을 피할 수 없는 경우가 있다. 이러한 경우에 캡처된 이미지의 motion blur 현상이 발생할 수 있으면, 이는 장노출(long exposure) 또는 긴 초점 거리(long focal length)에서 특히 두드러지게 나타난다.
이러한 문제를 완화하기 위한 방법은 주로 광학(optical) 및 기계적(mechanical) 영역에서 연구되어 왔다. 우선 optical 영역에서 안정화(stabilization)는 고비용의 맞춤 렌즈 혹은 저렴하지만 덜 효과적인 shift sensor를 사용하여 나타낸다. 반면 기계적 영역에서는 acuated gimbals 와같이 복잡한 광학 장비 없이 모든 카메라에 부착할 수 있다. 이러한 시스템은 많이 사용되지만 화면의 움직임이나 대기의 난기류로 인한 blur에 대해서는 제한적인 성능을 보이게 된다. 또한 기계식 안정화 장치의 가장 큰 문제점은 비용, 무게 및 전원 요구 사항으로 많은 시나리오에서 사용이 제한될 수 있다.
최근 전통 적인 이미지 처리 문제를 해결하기 위해 딥 러닝을 사용하여 접근하는 방식이 성공적으로 활용되어 왔다. 특히 burst and multi-frame imageing 분야는 denosing과 deblurring에 대한 다양한 작업으로 주목을 받고 있다.
이러한 방법들은 동일한 장면의 서로 다른 degraded realizations에 얽힌 정보를 활용하여 하나의 high-quality image를 만들게 된다.
이들은 이러한 개념을 이용하여 long-exposure의 강한 blur와 short exposure의 낮은 SNR 사이의 trade-off 와 함께 각각 짧은 시간동안 연속으로 캡처된 image burst를 사용하여 image stabilization을 진행할 것을 제안하고 있다.
이 두 가지의 설정을 통해 joint burst denoising and deblurring 으로 문제를 줄이게 된다. 대부분의 burst methods는 burst 전체의 데이터가 상호 보완적이라고 가정하지만, 이들은 pipline에 명시적으로 개입하여 noise 및 blur의 level의 다양성을 강제할 것을 추가로 제안하고 있다.

위의 그림은 이들이 제안하는 방법과 이전에 방법들을 비교한 것이다.
이들이 제안하는 방식을 보면 다른 방법들에 비해 상대적으로 blur와 noise를 상당히 깨끗하게 지워준다는 것을 알 수 있다.
2. Approach
latent scene이 시간 간격 [0, T]에 걸쳐서 카메라의 움직임에 의해서 캡처되는 시나리오를 가정한다.
이들은 시간 t에서 irradiance(방사조도) image를 latent irradiance E의 latent transformation

로 나타낸다. 즉 아래와 같은 식이 성립하게 된다.

irradiance image는 직접 관찰을 할수가 없다. 대신, 카메라는 n프레임 Y_1, ..., Y_n 의 이산 세트를 흭득하게 된다.
각 프레임이 캡처가 되는 시간은 다음 수식과 같다.

위 수식의 시간동안 캡처가 된다. 여기서 t_i는 셔터의 개방 시간을 나타내며

는 프레임의 노출 시간을 의미 한다.
각 프레임은 sensor forward model F를 통해 latent image와 관련이 있다. 이때 model F는 다음과 같다.

노출 시간이 상대적으로 낮다고 가정하면 burst의 각 frame은 imaging noise로 인해서 낮은 SNR을 가지게 된다. 또한 카메라 움직임으로 인해 프레임에 약간 blur가 생길 것이다.
이 낮은 SNR과 blur라는 두 가지 degradation 소스는 프레임의 노출 시간에 의해 제어가 되며 노출 시간이 길수록 SNR이 향상되고 블러가 강해지게 될 것이다. 이 반대의 경우도 마찬가지이다.
본 논문에서 저자의 목표는 latent irradiance image의 single sharp high-SNR 추정으로 프레임을 결합하여 장면의 얽힌 정보를 활용하는 것이다. 다음식을 보자..

위 수식에서 I 는 recontruction(inverse) operator(= 재구성 연산자) 이다.
이들은 카메라의 사용자 제어 매개변수와 동시에 재구성 연산자를 학습할 것을 제안하는데 이 경우 shutter schedule (셔터 일정?)은 {ti, ∆ti} 이다.
이것은 아래의 식과 같이 learning problem의 형식으로 이어지게 된다.

위 식에서

은 latent E와 estimated version인

사이의 불일치를 측정하는 loss function의 기대치를 나타내며 ∆ 는 burst parameters를 의미한다고 한다.
이제 저자들은 미분 가능한 forward와 inverse model의 구성과 learning scheme에 대해서 설명할 것이다.
3. Sensor forward model

이 섹션에서는 scene irradiance에서 시작하여 완전히 형성된 raw image로 끝나는 image process에 대해서 설명하고 있다. 이들은 일반적으로 Konnikrhk and Welsh[ High-level numerical simulations of noise in ccd and cmos photosensors: review and tutorial ]의 noise estimation(노이즈 추정)을 따르고 있으며 time-dependent와 눈에 띄게 지배적인 short exposure(단노출)에 집중하고 있다 한다.
간단하게, scene irradiance에서의 time-dependent와 단노출에 집중하여 raw image를 추출하겠다는 것이라 이해하면 될 것 같다.
3.1 Image formation
우선 이들의 model은 정적인 장면의 단노출 이미지를 caputring하는 움직이는 카메라에 대해서 설명하고 있다고 얘기한다. 즉, forward model을 통해서 생성되는 이미지는 움직이지 않는 고정된 피사체를 움직이는 단노출 카메라로 촬영한 이미지라고 생각하면 좋을 것 같다.
단순화를 위해서 카메라와 light source 모두 동일한 파장 λ 에 대해서 단색이라고 가정한다. 또한 장치별 매개변수는 일반적으로 manufacturers 에서 제공하므로 알려진 것이라고 가정한다.
3.1.1 From photons to electorns
E_t(x) 를 시간 t에서 픽셀 x의 irradiance(조도)라고 한다. 이는 photon flux(광자 플럭스)로 표현할 수 있다.

λ는 파장, A는 유효 픽셀 면적, h는 플랑크 상수, c는 빛의 속도를 나타낸다.
수집된 각 광자(photons)는 전하(electric)의 형태로 에너지를 축적하여 픽셀 내부에 광전자(photonelectrons)를 생성한다. 이 광전자의 mean amount는 아래의 수식과 같다.

여기서 [t, t + ∆t] 는 셔터가 열린 간격이며 "ηλ"는 파장 "λ"에서 픽셀의 quantum efficiency(양자 효율)이다.
3.1.2 Noise generation
광자가 픽셀의 유일한 전하원(sole source)이 아니다. 암전류(dark current)라고 하는 일정량의 전류는 scene이 어두워도 열적으로 적하는 축적(thermally deposits charge)한다. 생성되는 전자의 평균 수는 exposure time(노출 시간)에 따라 아래의 수식과 같이 linear하게 증가하게 된다.
※ 암전류 : 광자가 장치에 들어 가지 않는 경우에도 광전관 튜브, 광다이오드 또는 전하 결함 장치와 같은 감광 장치를 통해 흐르는 상대적으로 작은 전류 ※

여기서 I_0는 평균 암전류이고 q_e는 원소 전하(elementary charge)이다.
측정된 전자의 수는 불연속적인 특성으로 인해 포아송 통계에 따라 무작윈로 변동한다.
Shot noise라고 알려진 현상은 종종 Gaussian distribution을 통해서 근사화된다. 이 경우는 high-light regimes에서 유효한 과정이다. 그러나 본 논문에서는 shot noise가 다른 구성 요소를 지배하는 short exposure을 다루기 때문에 Poisson variable의 실현으로 광전자 생산을 모델링한다. 이 수식은 아래와 같다.

또 다른 주요 잡음원인 판독 잡음(readout noise)은 노출 시간(exposure time)과 무관하다. 이는 대부분 analog-to-digital converter(ADC)의 열 변동에 의해서 발생하며 zero-mean Gaussian distribution과 함께 device-specific standard deviation,

을 따른다. 따라서 수집된 총 전자 수는 아래의 수식과 같이 표현할 수 있다.
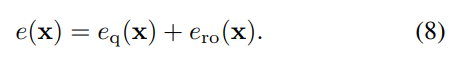
3.1.3 From electrons to digital numbers
픽셀 회로(pixel circuits)는 수집된 전자를 전압으로 변환한 다음 증폭되어 digital numbers(DNs)로 변환된다.
EMVA 1288 표준에 따라 이 process는 픽셀의 full-well capacity(FWC)에 대한 sensitivity가 감소하는 linear curve로 대부분 설명이 된다고 가정하자. 그럼 이 응답 함수를 다음과 같이 모델링할 수 있다고 한다.

이때 K는 overall system gain이며, τ_1 는 곡선이 strictly concave 해지는 treshold이다.
τ_1 + τ_2 = FWC 이다. 또한 DN은 이산 값을 가지므로 아래와 같이 양자화 함수를 합산해 준다.

이때 m은 픽셀당 bit 수 이다. 그리고 [ ] 는 반올림 작업을 나타낸다.
이를 통해, 픽셀 x에서 디지털 이미지의 DN 값은 아래와 같이 지정되게 된다.

여기서 dark noise
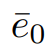
의 평균을 빼면 많은 카메라가 적용하는 일반적인 보정이 반영된다.
3.2 Exposure parametrization
Sensor forward model을 학습하기 쉽게 만들기 위해서 burst의 전체 시간 예산 T와 프레임 수 n을 고정하고 개별 프레임의 exposure parameters를 다음과 같이 parameterize 한다.

∆t_min : minimum exposure teim.
t_ro : 프레임 판독 시간 (2개의 연속 프레임 사이에 필요한 추가 blank time도 포함 된다.)
상대 프레임의 노출을 나타내는 parameter "αi" 는 다음과 같이 parameterize 될 수 있다.

σ 는 softmax를 의미 한다.

학습 가능한 카메라의 역할을 하는 parameter인 벡터 ∆는 burst가 사용 가능한 전체 시간 예산을 소비하는 경우 n-dimensional 로 설정이 가능하고, 그렇지 않고 모든 시간을 활용하지 않도록 하는 경우 (n+1)-dimensional 로 설정할 수 있다.
3.3 Numerical approximation
optimal burst exposure parameters ∆ 의 학습은 위에서 소개된 식 (5-11)에 의해 forward model의 미분 가능한 연산을 요구한다. 전체적으로 계산이 간단하게 이루어지지만 5, 7, 10의 경우에는 특별히 고려하여 근사화 해주어야한다고 저자는 이야기 하고 있다.
수식(5)의 forward pass는 식(4)에 따라 스케일링된 conntinuous irradiance function

의 시간 적분을 계산한다. 학습시, 시뮬레이션된 장면의 흐름에서 얻은 N ≫ n 의 균일하게 sampling된 irradiance values

sequence에서 사다리꼴 적분법을 통해 이 시간 적분을 근사화 할 수 있다고 한다.
4. Reconstruction network
이번 section에서는 위의 방법을 통해 얻은 burst frame Y_1, ..., Y_n 에서 깨끗한 irradiance image E를 estimating하는 inverse model을 얻는 것이다.
본 저자들은 video interpolation, super-resolution, deblurring, burst denoising 등에서 좋은 성능을 보이는 kernel prediction networks(KPN) 을 기반으로 flow model을 설계하였다.
논문에서 해결하고자 하는 문제는 같은 scene에서 서로 다른 noisy annd blurry realizatoins를 병합하는 것이기 때문에 KPN의 사용이 적절하다고 설명하고 있다. 이를 위해서 시간 및 공간적 variant kernels를 예측하고 이를 이용하여 캡처된 burst를 깨끗하고 선명한 image로 병합하였다.
고정 크기 kernel은 frame을 정렬하는 기능이 제한되어 있기 때문에 video deblurring 분야에서 일반적으로 적용되는 기준에 따라서 burst를 pre-warp 해주었다고 한다.
이전에 연구에서 가장 효율적인 옵션으로 pre-trained flow network를 사용하는 것을 제안하였었다.
그러나 본 논문에서의 문제는 exposure time이 학습되는 동안 input frame의 noise와 blur의 양이 변경될 것으로 예상되기 때문에 이전의 연구에서 사용되던 방법은 적용하기에 적절하지 않고 비실용적이다.
따라서 본 논문의 저자는 완변한 절렬을 위한 것이 아닌 kernel의 좁은 receptive field를 보상하기 위해 flow network parameter가 co-learned(공동 학습)되는 end-to-end training methodology를 선택하였다.
4.1 Flow network

위에 figure 4는 본 논문에서 사용된 flow network이다.
논문의 저자들이 사용한 flow network는 Kalantari and Ramaoorthi [ Deep hdr video from sequences with alternating exposures ]가 제안한 architecture를 따르고 있다고 한다.
sub-CNN은 5x5 convolution과 ReLU로 이루어져있는 구조이다.
flow network의 미리 선택된 reference인

를 따라 프레임

를 정렬하는 것을 목표로 한다.
연속된 동작 중에 전체 burst가 캡처되는 것이기 때문에 Y_i0은 다른 프레임들과 overlap 될 것으로 예상되어 정렬이 더 시워 는 중간 프레임으로 선택을 한다.
이들은 non-rigid motion(비강체 운동)과 parallax(시차)를 다루기 위해서 flow networks를 사용한다.
이 방법은 개별 이미지를 정렬하는데 이는 degraded input에서 실패하기가 쉽다.
그래서 해당 모델은 reference(Y_i0)의 neighboring frames(이웃 프레임)을 공동으로 정렬하여 누락된 정보를 보완함으로써 문제를 해결하였다고 한다.
위 figure 4의 flow-network에 대해서 좀 더 자세히 알아보자
우선 network의 input의 Gaussian pyramid 에서 flow를 개발하고 미세화하기 위해서 hierarchical approch(계층적 접근) 방법을 채택하여 사용하고 있다.
Coarse 에서 fine level 까지 전부 동인한 sub-CNN을 적용한다.
Coarsest level에서, 이들은 sub-CNN's의 출력을 displacement field로 처리하고, sub-CNN에 다시 공급하기 전에 이를 up-samplinng하여 다음 level에 적용한다.
그 후에 다음 output flow에서 upsampling된 flow와 합하여 다음 flow를 생성하고 반복한다.
이러한 구성은 large-scale과 high-precision에서 pixel displacements를 생성하는 이점이 있다고 설명하고 있다.
exposure time은 안정적이지 않기 때문에 burst의 밝기는 프레임마다 그리고 training 동안에 매번 다르다. 그러므로 프레임을 flow network에 input으로 공급해주기 전에 exposure time 예산의 일부에 따라서 프레임을 normalize 해준다.

4.2 Kernel prediction network

본 논문에서의 kernel prediction network는 Mildenhall et al [ Burst denoising with kernel prediction networks ]이 제안한 network중 noise-blind 버전을 사용하였다.
이 모델은 skip connection을 적용한 encoder-decoder 구조이며 input pixel의 adaptive kernel을 예측한다.
그런 다음 kernel이 적용되어 얻어진 모든 프레임을 결과 이미지로 병합해준다.
pixel-adaptive kernel을 사용하면 몇가지 이점이 있다고 저자들은 얘기하고 있다.
우선 corss edges의 risk없이 pixel 평균화를 통해 noise를 줄이고 균일하지 않은 blur를 수정할 수 있다. 이는 일반적으로 long focal lengths가 적용되는 문제에서 특히 두드러 진다고 한다.
또한 kernel은 최종 이미지의 각 영역에 대해 가장 신뢰성 있는 프레임을 선택함으로써 burst에 걸친 변동성을 활용할 수 있다고 한다. 이는 아래의 그림을 통해서 확인할 수 있다.

이러한 방법은 각 프레임의 exposure time 및 content에 영향을 받지만 flow network에 의한 alignmennt artifacts를 보상할 수도 있다. 따라서 이들은 original burst와 registered burst를 병합하여 이것이 다른 burst보다 더 선택될 수 있도록 하였다고 한다.
output을 생성하기 위해 먼저 결과 프레임의 pixel-wise mean을 아래의 수식과 같이 구한다.

위 수식에서

는 aligned frames(정렬된 프레임)이고
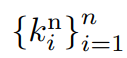

는 predicted location-dependent kernel이다.
⊗는 kernel의 적용을 의미 한다.
또한 perceptual quality를 증명하기 위해서 differentiable gamma correcting function Γ 를 적용하였다.
5. Training
5.1 Loss function
Ground-truth image E가 주어지면 이때 기본 loss function을 다음과 같이 정의 한다.

이때 ∇은 horizontal과 vertical이 결합된 sobel filter이며, µ는 고정 상수이다.
본 논문의 저자들은 급격한 output을 촉진하는 것을 확인하여 l1 loss를 사용하였으며 두 번째 항은 패턴화된 artifacts를 억제하기 위한 regullarization으로 적용이 된다고 한다.
본 논문의 실험에서 해당 loss가 좋은 결과를 가져오기는 하지만 flow network가 burst를 적절하게 alignment하지 못하기 때문에 predict된 kernel이

해당 수식을 무시하는 문제가 생긴다는 것을 발견하였다.
그러므로 이들은 프레임의 alignment를 장려하기 위해 annealed loss term을 사용할 것을 제안하고 있다.
annealed loss term은 heterogeneous timing regimes를 학습하는 것을 방해할 수 있으므로 이들은 제안하는 loss는 각 개별 frame에 loss를 적용하지 않았다.
대신 다음 수식처럼 각 kernel 항목을 합산하여 1x1 kernel을 생성하고 이를 사용하여 alignnment된 burst를 병합한다.

여기서 K는 해당 index kernel에 대한 합계를 나타내며, κ는 모든 2n-1 kernell에 대한 pixel-wise sum을 의미한다.
κ_a는

위 두 개의 식에 대한 pixel-wise sum을 의미한다.
최종적으로 저자들이 제안하는 전체 loss는 다음과 같다.
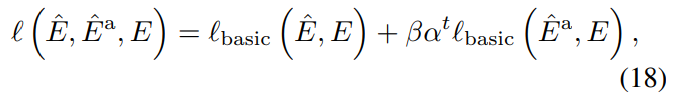
β, α ∈ (0, 1) 는 고정된 상수이며, t는 현재 iteration number 이다.
따라서 first phase의 training 의 loss는 flow network의 성능을 개선하여 kernel의 좁은 receptive field를 보상하는 gradients를 생성하게 된다.
6. Experiment


위의 Figure7-8, 11 을보면 기존의 방법들에 비해 눈에 띄게 motion blur와 noise가 개선되었다는 것을 확인할 수 있다.

Figure 9를 통해서도 영상의 개선이 굉장히 잘 이루어지는 것을 볼 수가 있다.

uniform and learned exposures에 대한 실험 결과를 나타낸 그림이다.
해당 논문은 CVPR poster로 소개되었던 논문이다. 지금까지의 denosing, deblurring을 해결하는 방식과 접근법이 다르다는 느낌을 많이 받은 논문이였다.
다른 방법들에 비해서 눈에 띄에 강한 blur에 대해서 복원이 잘된 사진들과 문제를 해결하기위한 접근법을 보아 한번쯤 해당 모델을 직접 실험을 해보는 것도 좋겠다라는 생각이 드는 논문이였다.
'AI > Vision' 카테고리의 다른 글
Invariant Information Clustering for Unsupervised Image Classification and Segmentation (0) 2023.02.13 NeRF : Representation Scenes as Neural Radiance Fields for View Synnthesis (0) 2022.12.19 Vision GNN : An Image is Worth Graph of Nodes (Review) (0) 2022.10.20 알고리즘 경량화 - 모델 압축 기법 (0) 2022.10.05 Emerging Properties in Self-Supervised Vision Transformer (1) 2022.09.29