-
NeRF : Representation Scenes as Neural Radiance Fields for View SynnthesisAI/Vision 2022. 12. 19. 18:51
ECCV
NeRF : Reprsentation Scenes as Neural Radiance Fidels for View Synthesis
Ben Mildenhall 1*, Pratul P. Srinivasan 1*, Matthew Tancik 1*, Jonathan T. Barron 2, Ravi Ramamoorthi 3, Ren Ng 1
NeRF는 view synthesis를 생성하기 위한 논문이다. 혁신적인 방법으로 기존의 방법들에 비해 높은 성능을 보이며 view synthesis 분야의 한 획을 그은 논문이다. NeRF의 단점을 보완하기 위한 논문들이 현재까지도 쏟아져 나오고 있으며 활발히 연구가 진행 중이다.
DOI : arXiv:2003.08934
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
We present a method that achieves state-of-the-art results for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views. Our algorithm represents a scene using a fully-con
arxiv.org
0. view synthesis
그럼 우선 view synthesis가 무엇인지부터 우리는 알아야 한다.

이미지 하나 또는 여러 개가 들어가면 continuous 하게 임의의 시점, 방향으로 물체를 바라보았을 때 어떻게 보일 지를 합성하여 만들어 주는 분야를 view synthesis라고 한다.
예를 들어 오른쪽과 왼쪽의 모습을 가지고 정면의 모습을 예측하는 것, 다양한 각도와 시점에서의 물체를 통해 가지고 우리가 모르는 각도와 시점에서의 물체의 모습을 생성하는 것이다.
즉, 간단하게 말하면 다양한 시점을 통해 가지고 있지 않은 모르는 시점에서의 물체의 모습을 예측하는 것이다.
위 그림을 정리해보면 다음과 같다.
Input Image : 불연속적인 시점에서 촬영/랜더링 된 이미지
Optimize NeRF : Perspective view 카메라가 원근법을 적용할 수 있는 형태, object나 scene 자체를 학습한다.
Render new views : 새로운 random 한 view
1. Neural Radiance Field (NeRF)
View synthesis가 이전 섹션에서 무엇인지 알아보았다. 그럼 NeRF란 무엇일까?
기존의 Image는 각 위치에 Pixel 값을 저장한 Table 형태인 반면 Neural Radiance Field (NeRF)는 각 위치의 값을 input으로 주면 output으로 RGB 값을 연산하는 함수의 형태이다.

NeRF function 위 그림의 F와 같이 NeRF를 정의할 수 있다.
위의 그림을 보면 x, d를 통해 c, σ 를 얻음을 확인할 수 있다.
이때 input과 output을 확인해 보자.
- Input : x와 d각각 coordinate(위치, 좌표)와 direction(보는 방향)을 의미한다.
- output : c와 σ 각각 RGB 값과 Density를 의미한다.
direction이 input에 필요한 이유는 보는 방향에 따라서 RGB 값이 변할 수 있기 때문이다.
output의 density는 투명도의 역수 개념으로 density가 높으면 불투명한 것이고, 낮으면 투명한 것이다. 즉, 기체 혹은 유리 같은 것들은 Density가 낮을 것이다.
다시 정리를 하면, 위치와 보는 방향을 input으로 RGB와 densitiy를 얻는 F_Θ 를 얻는 것이 이 논문의 궁극적인 목적이고
이때 이 F_Θ을 어떻게 얻을 것이냐?라는 문제에서 F_Θ를 deep neural net(DNN)으로 정의하고 학습을 통해 얻어보자!라고 제안하는 것이 본 논문이다.
F_Θ는 주어진 이미지들을 이용하여 학습을 진행하게 된다.
이 의미는 DNN을 initialize 해서 대상 하나에 대해서 학습을 하는 과정을 랜더링이라고 생각하여 학습을 진행하게 되는 것이다. 어떻게 보면 이는 zero-shot learning의 일종이라고 볼 수 있다.
쉽게 말하면 train을 잘해서 다른 데이터에 대해서 test 할 때 그 weight를 쓰겠다!라는 개념이 아니라 train 자체가 inference가 되는 것이다. 이러한 학습 방식은 Deep Image Prior 또는 Zero-Shot Super Resolution과 비슷한 류의 알고리즘이라고 생각해도 좋다.
간단히 정리해보면, Train을 미리 하는 것이 아닌 test시에 input이 들어오면 그 input에 대해서만 학습을 새로 하는 개념인 것이다.
2. Overview of neurall radiance field representation

위 그림은 본 논문에서 저자들이 제안하는 방식을 전체적으로 나타낸 flow이다.
Position + Direction을 input으로 Color + Density를 얻고 이를 이용하여 Volume Rendering을 진행하고 loss 연산되는 순서를 가지고 있다.
2.1 Ray
이전에 Color와 Density를 얻는 함수에 대해서 확인을 해보았다. 이 함수를 통해 우리가 원하는 위치의 pixel을 얻기 위해 Ray라는 개념을 사용하여 연산을 진행하게 된다.

공간상에서 점 하나와 각도가 주어지면 직선을 상정할 수 있고, 그 직선 위에 sampling 되어 있는 object들의 particle들의 집합으로 만들어지는 선을 Ray라고 부른다.
직선상의 모든 물체의 particle 들은 우리가 원하는 최종 pixel하나의 RGB 값을 만들기 위해서 모두 영향을 주고 있을 것이다.
예를 들어 특정 카메라가 우리를 찍는다고 생각해보자.
카메라와 나 사이에는 여러 가지 물체 혹은 빛이 있을 것이다. 이러한 것들은 내가 촬영될 때의 pixel값에 영향을 미치게 될 것인데 빛이 많은 부분의 pixel을 영향을 받아 밝아지게 될 것이고 유리가 등이 있다면 내가 가려진 부분의 색상이 흐려지는 등의 영향을 받게 될 것이다.
이렇듯 Ray위에 있는 모든 particle들은 카메라에 우리가 어떠한 픽셀로 담기게 될 것인가에 영향을 주게 되는 것이다.
2.2 Volume Rendering with Radiance Fields
어떻게 원하는 Pixel 값을 얻고 volume rendering을 진행하는지에 대해서 알아볼 것이다.
우선 원하는 Pixel 값을 구하는 방식은 다음과 같이 정의할 수 있다.

수식 (1) C(r)을 기댓값이라 해석하게 되면 RGB(확률 변수), Density(확률)이라고 볼 수 있으며 Volume Rendering은 미분이 가능한 연산이기 때문에 backpropagation이 가능하다.
이때 r(t) = o + td이다.
한 Ray위에 존재하는 Point 들의 RGB 값들의 weighted Sum으로 구할 수 있다. 즉, 수식에서의 C값들의 weighted sum을 통해 원하는 위치의 pixel의 값을 얻는 것이다.
원하는 Pixel을 얻는 projection에서 원하는 지점의 pixel이 density가 클수록 weight가 커져야 하며, 그 지점을 가로막고 있는 점들의 density의 합이 작을수록 원하는 지점의 weight가 커져야 한다.
왜 위와 같아야 하는지를 자세히 살펴보자.

위와 같은 그림의 경우 벽에 가려져서 우리가 보는 방향에서 사람이 보이지 않는다.
이 경우 사람 앞의 벽의 density가 매우 높아 사람이 보이지 않을 것이다.
이렇듯 해당 사람의 pixel을 얻기 위해서는 사람의 density도 매우 중요하겠지만 벽까지의 density도 굉장히 중요하다.
사람이 보이기 위해서는 노란색 부분의 density가 낮아야 비로소 사람이 보이게 될 것이다.
이러한 것을 적용하기 위해서 위의 수식에서 T(t)가 존재하는 것이다.
전체 수식에서 적용된 T(t)의 수식은 다음과 같다.

t_n : 이미지의 시작점
t : 우리가 원하는 c의 위치
위 수식은 t_n ~ t까지의 density를 모두 적분하고 그것을 exponential의 음수로 올려준 것으로 이를 통해 density가 큰 것이 가리고 있으면 값이 작아지게 될 것이다.

수식 (2) 위의 수식은 Continuous 한 object를 배우게 하기 위해서 사용되는 수식으로
Ray를 N 등분하고 그 안에서 random 하게 sampling 하여 학습에 사용될 particle을 결정하게 된다.
위의 두 수식 (1), (2)를 통해 최종적으로 아래와 같은 식을 얻을 수 있게 된다.

3. Hierarchical volume sampling
본 논문에서 제안하는 방법은 "Coarse Network"와 "Fine Network" 두 가지 network를 사용하여 학습을 진행한다.
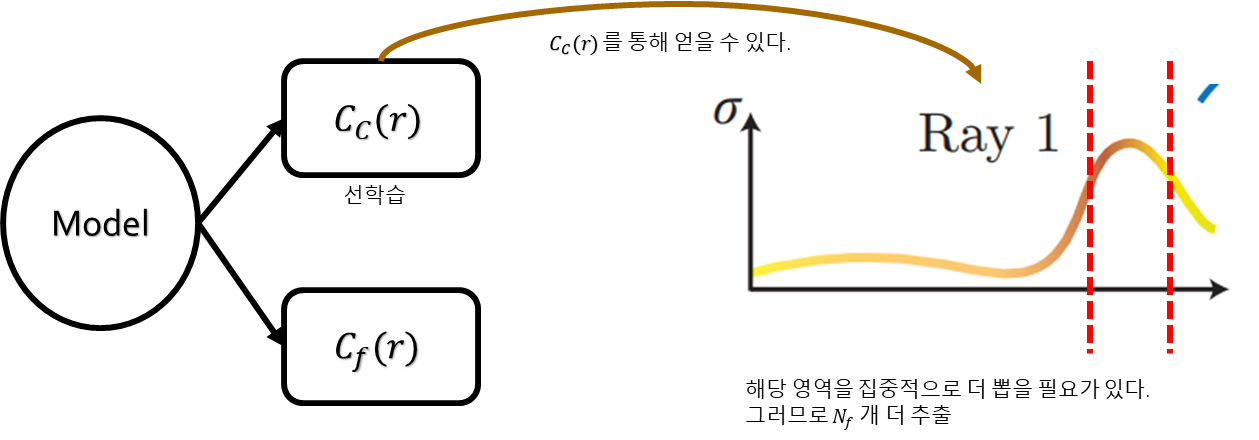
앞에서 소개된 random sampling 방식을 통해 N_c개의 t를 추출하고 이를 이용해서 "Coarse Network (= 그림의 C_c(r))"를 학습하게 된다.
"Coarse Network"를 통해 얻은 Distribution(T(r))를 얻고 σ(density) 높은 해당 부분에서 N_f개의 t를 추가적으로 더 뽑는다. σ가 높다는 것은 중요한 부분이라는 것을 의미하니 그 구간의 t를 추가적으로 뽑아 학습이 원활하게 이루어지도록 하는 전략이다.
총 N_c + N_f 개의 sample을 이용하여 "Fine Network"를 학습시키게 된다.
4. Position encoding
NeRF는 coordinate(x, y, z)와 direction(x', y', z') 총 6차원의 input이 neurall net을 거쳐서 R, G, B, σ 4차원의 값을 뽑아내게 된다.

이때 보지 못했던 위치에 대해서는 위 그림과 같이 선명하지 못한 결과를 얻게 되는데 이는 정보가 부족해서 information pumping이 원활하게 이루지지 않기 때문이다.
이러한 문제를 해결하기 위해서 본 논문에 저자들은 position encoding을 사용하였다.

position encoding 수식 위 수식을 보면 p에 x, y, z 중 하나를 입력하고 수식을 통해 sin, cos으로 차원을 뻥튀기해주게 된다.
이렇게 되면 high dimension으로 정보를 늘려주게 되며, high frequency 영역도 표현할 수 있게 된다.
L = 10 for γ(x) and L = 4 for γ(d)으로
위치에 대해서는 3 -> 60으로 늘어나며, 방향에 대해서는 3 -> 24로 늘어 난다.
5. Model Architecture

Model의 architecture는 매우 간단하다.
Multi-Layer Perceptron(MLP)으로 구성되어 있으며 위치 정보로 학습을 시작한다.
중간에 위치 정보에 대한 입력을 한번 더 주게 되는데 이는 정보가 layer를 지나며 소실될 것을 우려하여 추가해주는 것이다. 그 후 마지막에 direction(방향) 정보를 입력해주고 density를 얻게 된다.
6. Loss
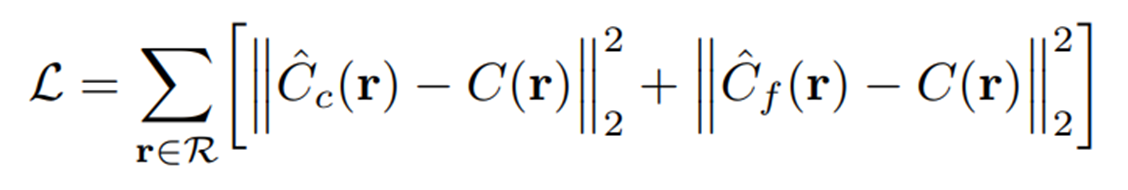
Loss는 특별한 것 없이 간단하게 MSE(L2 loss)를 사용하였다.
7. 문제점
해당 논문은 view synthesis 분야에 한 획을 그은 아주 중요한 논문이다. 그러나 좋은 성능만큼 문제점도 명확하다.
1. 모델의 학습시간의 굉장히 오래 걸린다.
- V100 GPU 기준으로 학습시간이 대략 1~2일 정도 필요하다고 한다.
- 랜더링을 하는데 1 frame 당 대략 30초를 필요로 한다.
- 즉, 사실상 real-time으로 사용하는 것은 불가능하다.
2. Model 하나 당 하나의 scene이 학습되는 것이기 때문에 매번 새로운 학습을 필요로 한다.
- NeRF의 경우 pixel 단위로 generalize 되기 때문에 한 model당 하나의 scene에 대해서만 좋은 성능을 가진다.
- 이것은 다양한 scene에 대해서 general 한 model은 아니라는 것을 의미한다.
3. Static 한 scene에 대해서만 성능이 좋다.
- 움직이는 피사체가 scene에 존재하는 경우 많은 noise가 발생하게 된다.
그렇기 때문에 단점을 보완하고 성능을 올리기 위한 NeRF의 후속 연구 논문들이 쏟아져 나오고 있다.
8. 정리
논문을 통해 NeRF의 대해서 알아보았다. 현재 이 분야에서 가장 중요하고 빠르게 발전하고 있는 중요한 방법이 NeRF라고 생각한다. 가볍고 간단한 구성의 model을 사용하여 최적의 성능을 뽑아낼 수 있으며 성능이 다른 무거운 model을 사용한 방법들에 비해서 상당히 좋다는 것에 큰 의의가 있다고 생각한다.
분명 NeRF는 명확한 문제점이 있지만 가지고 있는 장점이 이 문제점을 덮기에는 충분하다고 생각한다. 그렇기 때문에 단점을 보완하는 후속 논문들이 NeRF가 등장한 시점부터 지금까지도 많이 나오고 있는 것이 아닐까 생각한다.
view synthesis 분야는 어디에든 적용이 될 수 있는 기술이라 생각하기 때문에 vision task를 다루는 사람이라면 꼭 알아야 하는 논문이라고 생각한다.
9. References
•https://www.matthewtancik.com/nerf•https://carmencincotti.com/2022-05-02/homogeneous-coordinates-clip-space-ndc/'AI > Vision' 카테고리의 다른 글
ConvMixer : PATCHES ARE ALL YOU NEED? (0) 2023.05.08 Invariant Information Clustering for Unsupervised Image Classification and Segmentation (0) 2023.02.13 Digital Gimbal : End-to-end Deep Image Stabilization with Learnable Exposure Time (0) 2022.12.13 Vision GNN : An Image is Worth Graph of Nodes (Review) (0) 2022.10.20 알고리즘 경량화 - 모델 압축 기법 (0) 2022.10.05