-
StyleSync: High-Fidelity Generalized and Personalized Lip Sync in Style-based GeneratorAI/Vision 2024. 5. 8. 18:24
CVPR 2023
StyleSync: High-Fidelity Generalized and Personalized Lip Sync in Style-based Generator
해당 논문은 특정 audio에 맞게 특정 대상이 립싱크를 하는 영상을 생성하는 방법에 대한 논문이다.
이러한 generating lip-synced video는 게임 및 영화와 같은 영상 콘텐츠를 다루는 분야에서 많이 사용을 하고 연구를 하고 있다.
평소 영상 컨텐츠 업계에 관심이 많이 흥미롭게 읽을 수 있었던 논문이었다.
Doi: 10.1109/CVPR52729.2023.00151
CSDL | IEEE Computer Society
www.computer.org
1. Introduction
[ Generating lip-synced video ]
Digital human, audio dubbing, film-making and entertainment 등 다양한 분야에서 사용되고 있다.
대부분의 lip-synced video를 만들기 위한 기존 방법들은 역동적으로 이야기하는 머리를 만다는 것에 집중한다.
이러한 설정으로 만들어진 결과는 영상에서의 기존 배경과 혼합되기가 어렵다.

Generating lip-synced video 예시 오디오 더빙과 같은 시나리오에서 중요한 요구사항은 "장면의 다른 부분은 변경하지 않고 입이나 얼굴만 원활하게 변경"하는 것이다.
그러므로 배경과 혼합되기 어려운 기존의 방법들을 해당 시나리오에 사용하기에는 문제가 있다.
[ 모든 길이의 video에서 high-fidelity lip-synced 결과를 얻기 위해서 해결해야 하는 문제 ]
직관적으로 lip-sync 품질은 원래 target frame information의 보전과 자연스럽게 모순이 되게 된다.
즉 높은 품질의 lip-sync 결과를 생성하려고 할 때, 원본 video의 frame 정보를 그대로 유지하려는 노력과는 반대되는 결과를 낳을 수 있다는 것이다. 그러므로, lip-sync 과정에서 원본 audio와 lip motion을 정확히 맞추려 하면, 원본 video의 자연스러운 특성이나 디테일을 손상시킬 수 있게 된다.
Few-shot meta-learning이 talking head를 생성하는 데 효과적인 것이 입증되었지만 이러한 기능을 lip-syncing pipeline에 포함시키는 방법은 탐색되지 않았다.
위와 같은 문제점을 해결하기 위해 알아야 하는 방법은 아래와 같다.
1) 정확한 audio information expression과 원활한 local alternation을 모두 지원하는 강력한 generative backbone network를 효율적으로 쉽게 설계하는 방법
2) 제공된 정보를 최대한 효과적으로 활용하고 personalized properties를 generalized model에 포함시키는 방법
2. Methodology
[ Task Formulation ]
Goal: 제공된 audio와 target person의 lip motion을 동기화하고 원래 target video에 원활하게 합성
해당 논문에서는 턱과 뺨을 포함한 얼굴의 하반부를 가리고 이를 복원하는 방식의 "self-reconstruction"을 적용하여 model을 학습하였다.
Target video, audio, masked target frame과 random reference frame을 아래와 같이 정의한다.
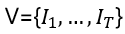
Target video 
audio 
masked target frame 
random reference frame Target video V의 T frame이 주어지면, 턱과 뺨을 포함한 얼굴 하반부 절반을 M으로 maskin한고, 이를 audio a로 얼굴 전체를 복구하는 것이다.
이때 masked target frame에는 입과 턱 모양에 대한 정보가 제공되지 않으므로, 훈련 중에 random reference frame을 활용해서 원하는 context를 제공한다.

Proposed Model 2.1 Modifying Style-based Generator for Lip Sync
[ Style-based Generator Overview ]
StyleGAN2 architecture를 사용하여 backbone을 구축한다.
StyleGAN2은 style vector w를 입력으로 사용하며, 이는 training 동안 총 L개의 generative layer에서 modulate convolution operation에 사용된다.
Inference 중에는 각기 다른 layer에서 다른 w를 사용할 수 있으며, 이로 인해 W+ space가 형성된다.
W+ space는 W={w_1, ..., w_L}이며, 각 layer별로 조정된 style vector들의 집합니다.

빨간 영역이 style-based generator이다. [ Mask-based Spatial Information Encoding ]
Goal: reference image의 도움으로 target frame에 lip-sync 된 입을 원활하게 혼합하는 것을 목표로 한다.
Face restoration and swapping을 연구한 이전 연구들에서 content-guided fature map이 generative model의 표현력을 해치지 않으면서 StyleGAN layer에 noise처럼 첨부될 수 있다는 것을 입증하였다.
이러한 context-rich noise N={N_1, ..., N_L} 은 encoding 된 visual 정보의 원래 spatial structure and attributes 정보를 유지하며 이를 생성 과정에 반영할 수 있게 된다.
이를 통해 보다 정확하고 자연스러운 이미지 생성이 가능해진다.

이러한 특성은 reference image내에 있는 attribute 정보를 활용할 수 있는 방법을 제공하게 된다.
mask 된 input과 reference input을 함께 concatenate 하여 framework의 visual input으로 feature map F_f를 사용하여 encoding 한다.

이때, 가장 간단한 설정은 F=N이다.
하지만, lip motions를 생성하는 목표는 원래 얼굴 구조와 다른 동적 생성을 하는 동시에 얼굴의 정체성을 유지해야 하므로 face restoration and swapping과 같은 이전의 방법들과는 다르다.
그러므로 같은 protocol을 채택하게 되면 reference image I_ref의 영향을 크게 받을 수 있다.
이러한 문제를 해결하기 위해 low-level information of F에 원하는 것보다 더 많은 얼굴 구조 정보가 주입되었음을 식별하고, 결과적으로 face feature의 low-level part of information을 직관적으로 마스킹한다. 최종 수식은 아래와 같다.

이때, 1은 M과 같은 크기의 all-one matrix이다.

빨간 영역이 Face Encoding이다. [ Style Information Encoding ]
이전 연구들에 따라, audio dynmaics와 facial 정보를 style-based generator의 style space에 encoding 한다.
Audio feature f_a는 encoder E_a에서 encoding 되며, face feature f_f는 face encoder E_face의 bottleneck 부분이다.
w = concat(f_a, f_f)이다.
Reference frame의 정보가 이미 spatial noise encoding을 통해 generator에 통합되었기 때문에, face feature의 통합은 필요하지 않다. f_f의 유무에 따른 차이가 미미함을 실험을 통해 확인했지만, 일반적인 관행에 따라 해당 설계를 유지하였다고 한다.

[ Ingredients for Personalization ]
StyleSync: 단순하며 personalized lip-sync modeling의 잠재력을 가지고 있다.
특정 이미지를 복구하기 위해 기존 StyleGAN2의 W 공간에서 W={ w+∆w_1, …,w+∆w_L }로 확장하는 것이 필수적이다.
또한, 최근 특정 target에 맞은 network의 fitting 능력을 향상시키기 위해 generator의 parameter를 조정하는 방법을 연구하고 있다.
따라서, StyleSync의 generator는 특정 person에 맞게 제한된 parameter shift ∆P를 학습한다.
이러한 개인화 요소는 일반적으로 훈련 절차 동안에는 최적화되지 않는다.
두 설정 간의 일관성을 유지하기 위해, 일반 모델에서는 ∆W=0 and ∆P=0으로 설정한다.
이는 특정 사용자의 데이터를 기반으로 한 후속 과정에서만 적용되며, 모델의 일반적인 학습과는 분리되어 진행된다.

2.2 Backbone Training Objectives
전체 backbone network는

의 6-channel concatenate와 동시에 audito clip a_t를 input으로 받는다.
[ Reconstruction Loss ]

Pixel-level reconstruction loss L_rec 은 이들의 작업을 위한 기본적인 training loss이다.
L1과 perceptual loss를 조합하여 사용한다.
[ Adversarial Loss ]

StyleGAN2에서와 같은 discriminator D를 사용하여 adversarial training을 직접 적용한다.
이때, discriminator의 weight를 StyleGAN2에서 pretrained 된 버전으로 initialize 한다.
[ Lip-Sync Loss ]

Visual encoder S_v와 audio encoder S_a를 포함하는 SyncNet을 훈련한다.
이는 visual and audio clip이 시간적으로 정렬되었는지 contarstive loss를 사용하여 식별한다.
Generator를 training 할 때, 각 inferece step에서 한 batch내에 5개의 연속된 아래와 같은 frame

을 예측하고 SyncNet의 도움으로 training을 supervise 한다.
최종 Loss는 아래와 같다.

2.3 Personalized Optimization
Backbone network trianing을 완료하면 임의의 대상에 대해 고행상도의 lip-sync 결과를 즉시 생성할 수 있게 된다.
그러나 모델이 일반적인 방식으로 훈련되었기 때문에, 다른 사람들 간에 생성된 lip motion의 움직임 패턴은 기본적으로 동일하다.
다른 정체성마다 다른 말하기 스타일을 가지고 있으므로, 원본 template video와 함께 이러한 personalized 속성을 포착한다.
Original video의 1분 미만만 주어지는 few-shot setting에 중점을 두어 학습을 진행한다.
[ Basic Learning Setting ]
Backbone과 유사하다.
Template video와 audio를 아래와 같이 정의하자.

template video 
audio 이를 가지고, training sample로 random frame을 선택한다.

ramdom frame 기존 loss로 전체 절차를 지속적으로 supervise 한다.
E_a encoder는 사람에 구애받지 않는 음성 내용 정보를 encoding 하기 때문에 personalized optimization 단계 동안 고정된다.
반면, E_face는 대상 인물 속성 정보를 encoding 한다. 이때, 과적합을 피하기 위해 단일 인물에 대한 매개변수를 최적화하지는 않는다.
[ Style Space Optimization ]
W+ space는 입 모양 움직임과 고수준의 얼굴 스타일 정보를 모두 포함한다.
이를 최적화하는 것은 이상적으로 특정 인물의 입 모양 패턴을 개인화하는데 도움이 될 것이다.
이전의 연구인 E4E에서 원래 W space 주변에서 작은 변위를 학습하면 이미지의 inversion quality를 확장하고 강력한 편집기능을 구현할 수 있음을 확인하였다.
따라서, encoding 된 얼굴 특성 f_f 를 기반으로 몇 개의 MLP 층을 가진 MLP_∆w 를 사용하여 일련의 ∆w=MLP_∆w (f_f) 를 비슷한 방식으로 학습할 것은 제안한다.[ Generator Tuning ]
Generator는 synthesizing and blending 품질을 가장 많이 결정하는 요소이다.
개인화 데이터와 함께 generator G의 parameter P가 ∆P로
[ Learning Objectives ]
Personalized optimization procedure의 최종 학습 목표는 아래와 같다.


3. Experiment



데모 링크: https://hangz-nju-cuhk.github.io/projects/StyleSync
StyleSync: High-Fidelity Generalized and Personalized Lip Sync in Style-based Generator
StyleSync: High-Fidelity Generalized and Personalized Lip Sync in Style-based Generator 1. Department of Computer Vision Technology (VIS), Baidu Inc., 2. Tsinghua University, 3. The University of Sydney, 4. S-Lab, Nanyang Technological University. The IEEE
hangz-nju-cuhk.github.io
'AI > Vision' 카테고리의 다른 글
Get a Model! Model Hijacking Attack Against Machine Learning Models (0) 2024.08.07 DDPM: Denoising Diffusion Probabilistic Models (0) 2024.08.06 Prototypical Contrastive Learning of Unsupervised Representation (1) 2024.02.05 Vision Transformer with Deformable Attention (0) 2023.09.14 Vision Transformer (0) 2023.09.14