-
Get a Model! Model Hijacking Attack Against Machine Learning ModelsAI/Vision 2024. 8. 7. 18:15
Network and Distributed System Security Symposium
Get a Model! Model Hijacking Attack Against Machine Learning Models
Ahmed Samlem, Michael Backes, Yang Zhang
본 논문은 Hijacking Attack 방법을 제시하는 논문이다. 해당 논문을 통해 인공지능 시스템을 제공하기 전 보안에 대해서 다시 한 번 더 생각하게 되는 논문이었다.
DOI: https://doi.org/10.48550/arXiv.2111.04394
Get a Model! Model Hijacking Attack Against Machine Learning Models
Machine learning (ML) has established itself as a cornerstone for various critical applications ranging from autonomous driving to authentication systems. However, with this increasing adoption rate of machine learning models, multiple attacks have emerged
arxiv.org
0. Background
0.1 연합학습(Federated Learning)

연합학습 프로토콜, 출처: https://hyungbinklm.tistory.com/5 분산 시스템에서 사용되는 머신러닝 방법으로 여러 기기나 클라이언트에서 Data를 수집하고 local에서 모델을 학습시킨 후, 중앙 서버로 업로드하여 전체적인 모델을 개선하는 방법이다. 연합학습은 개인 정보 보호를 강화하고, 대역폭과 저장 용량 문제를 해결하는 데 효과적입니다.
그렇다면 기존의 머신러닝은 어떨까?
기존의 머신러닝은 중앙서버에서 모든 데이터를 수집한 후, 중앙 서버에서 모델을 학습시키는 방법을 사용한다. 이로 인해 개인 정보 보호 문제와 대역폭과 저장용량등의 문제가 발생할 수 있다.
그럼 이제 연합학습의 단계를 알아보자!
연합학습의 학습 단계는 아래와 같다.
- 클라이언트에서 데이터 수집: 분산된 여러 클라이언트에서 데이터를 수집
- Local에서 모델 학습: 각 클라이언트에서는 local에서 데이터를 사용하여 모델을 학습
- 중앙 서버 업로드: 각 클라이언트에서 학습된 모델은 중앙 서버로 업로드된다.
- 중앙 서버에서 모델 결합: 중앙서버에는 각 클라이언트에서 학습된 모델을 결합하여 전체적이 모델을 개선한다.
위와 같은 과정을 통해 중앙 서버로 데이터를 보내지 않으며, 개인 정보 보호에 우수한 성능을 가질 수 있다. 또한 대규모 데이터를 다룰 때 대역폭과 저장용량 문제를 해결할 수 있다. 이러한 연합학습은 IoT기기, 스마트폰, 자동차등 다양한 분야에서 적용이 되고 있다.
연합학습의 장단점을 알아보자
장점
- 개인 정보 보호
연합학습은 각 클라이언트에서 수집된 데이터를 중앙 서버로 전송하지 않으므로, 개인 정보 보호에 우수한 성능을 보인다. - 대규모 데이터 처리
데이터를 로컬에서 처리하고, 중앙 서버로 전송하지 않기 때문에 대규모 데이터를 다룰 때 대역폭과 저장 용량 문제를 해결할 수 있다. - 분산 시스템 활용
분산 시스템 환경에서 사용이 가능해서, 여러 클라이언트에서 모델을 학습하고 결합할 수 있다. - 분산된 데이터 활용
분산된 여러 클라이언트에서 모델을 학습하고 결합함으로써, 전체 데이터셋을 활용한 것과 유사한 성능을 얻을 수 있다.
- 장점
- 개인 정보 보호
연합학습은 각 클라이언트에서 수집된 데이터를 중앙 서버로 전송하지 않으므로, 개인 정보 보호에 우수한 성능을 보인다. - 대규모 데이터 처리
데이터를 로컬에서 처리하고, 중앙 서버로 전송하지 않기 때문에 대규모 데이터를 다룰 때 대역폭과 저장 용량 문제를 해결할 수 있다. - 분산 시스템 활용
분산 시스템 환경에서 사용이 가능해서, 여러 클라이언트에서 모델을 학습하고 결합할 수 있다. - 분산된 데이터 활용
분산된 여러 클라이언트에서 모델을 학습하고 결합함으로써, 전체 데이터셋을 활용한 것과 유사한 성능을 얻을 수 있다.
- 개인 정보 보호
- 단점
- 불안정성
클라이언트 간의 하드웨어 및 소프트웨어 환경, 데이터의 차이 등으로 인해 모델의 안정성이 떨어질 수 있다. - 품질 관리의 어려움
중앙 서버에서 각 클라이언트의 학습 모델 품질을 제어하는 데 어려움이 있다. - 보안 문제
각 클라이언트의 로컬 환경에서 발생할 수 있는 보안 문제를 제어하기 어렵다. - 대역폭 제한
클라이언트의 대역폭이 제한적일 경우, 모델 업로드 및 다운로드가 지연될 수 있다. - 클라이언트 참여 문제
일부 클라이언트가 참여하지 않을 경우, 모델의 품질이 저하될 수 있다.
- 불안정성
1. Introduction
Machine learning (ML)은 autonomous driving, financial/banking application, and authentication systems와 같은 다양한 시스템에서 사용되고 있다. 이때 대부분의 ML은 좋은 성능을 가지기 위해 아래와 같은 두 가지 요구사항을 가진다.
- High computational power
- High-quality training dataset
하지만 이러한 요구사항은 개인이 스스로 ML 모델을 학습하는 것에 어려움을 만듭니다.
이러한 어려움을 해결하기 위해서 여러 당사자가 공동을 ML 모델을 구축하는 연합학습(Federated Learning)이라는 새로운 패러다임이 제안되었다.
하지만 ML의 교육과정에서 새로운 당사자를 포함하면 새로운 보안 및 개인정보보호 위험이 발생할 수 있다. 즉, 공격자가 ML 모델의 훈련을 조작할 수 있는 "attack surface"를 만들 수 있다는 위험이 존재한다. 이러한 유형의 공격을 "Training time attack" 이라 하며 예로 backdoor attack, data poisoning attack 등이 존재한다.
1.1 Contributions
해당 논문에서는 새로운 training time attack 방법인 "model hijacking attack"을 제안한다.
구체적으로, 공격자는 data poisoning을 수행하여 특정 task(original task)를 위해 설계된 target ML 모델을 공격자가 정의한 hijacking task를 수행할 수 있도록 용도를 변경한다. 이러한 target model의 용도 변경은 대상 모델 소유자가 탐지하지 못하도록 은밀하게 수행되어야 한다.
1.1.1 예상 피해 시나리오
1.1.1.1 예상 피해 시나리오 - 1
Model hijacking attack은 training time attack 이므로 공격자는 아래와 같은 두 가지 차원에 대해 은밀성을 적용해야 한다.
- Original task과 관련돼서 target model의 유용성을 위태롭게 해서는 안된다.
- Poisoning data가 training dataset의 동일한 분포의 데이터와 유사하게 보이도록 위장되어야 한다.
공격자는 Model hijacking attack을 사용하여 target model을 hijacking 하여 모델의 소유자가 눈치채지 못하게 의도하지 않은 ML 작업을 수행할 수 있다.
이를 통해 모델의 소유자가 자신의 모델이 불법적이거나 비윤리적인 서비를 제공한다는 누명을 쓸 수 있기 때문에 모델 소유자에게 책임 위험이 발생할 수 있다. 해당 문제가 발생할 수 있는 공정성 위반 시나리오의 예시는 아래와 같다.
- 공격자는 benign image classifier를 포르노 영화의 얼굴 인식 모델에 도용하거나 심지어 그러한 영화를 다른 카테고리로 분류할 수 있도 있다.
- Hijacking 한 model을 사용하여 얼굴 속성을 이용해 사람들의 성별을 분류
이렇게 되면, 하이재킹 된 모델 소유자의 의도치 않은 책임하에 공개 모델이 불법적이거나 비윤리적인 서비스를 제공하게 된다.
1.1.1.2 예상 피해 시나리오 - 2
Model hijacking attack으로 인해 발생할 수 있는 또 다른 위험은 parasitic computing이다.
공격자는 자신의 모델을 호스팅 하는 대신 application을 구현하기 위해 public free access 권한을 가진 모델을 hijacking 할 수 있다. 이를 통해 공격자는 자신의 모델을 훈련하는 비용을 절약할 수 있다. 그러나 더 중요한 것은 공격자가 자신의 ML모델을 유지하는 비용을 절약한다는 것이다.
예를 들어, 모델의 유럽에 구축하고 호스팅 하는 경우 구글에서 시간당 0.11~2.44 달러의 비용이 소요될 수 있다고 한다.
2. Model Hijacking Attack
2.1 General Attack Pipeline
- Model hijacking attack을 수행하기 위해 공격자는 먼저 hijacking dataset을 만든다.
- 그 후, 다음 hijacking dataset의 각 label에 대해 원래 dataset의 label과 연결할 mapping을 정의한다. 이 mapping 된 label은 target model을 poisoning 할 때 실측 정보로 사용된다.
- 공격자는 target model의 training dataset를 hijacking dataset로 poisoning 하고 target model이 훈련, 즉 hijacking 될 때까지 기다린다.
- Model이 hijacking 되면 공격을 시작하기 위해 공격자는 hijacking sample을 생성하고 hijacked model에 query 한다.
- 마지막으로, 공격자는 (공격의 초기화 시 수행된 동일한 mapping의 역을 사용하여) 예측된 출력을 hijacking task의 해당 label에 다시 mapping 한다.
Model hijacking attack을 수행하기 위한 가장 간단한 접근 방식은 target model의 훈련 데이터 세트를 hijacking dataset로 직접 poison 하는 것이다. 그러나 이 접근 방식의 주요 단점은 원본 데이터 세트와 하이재킹 데이터세트의 샘플이 크게 다를 수 있기 때문에 쉽게 감지될 수 있다는 것이다.
이러한 한계를 극복하기 위해 target model을 poison 하는 데 사용되는 sample이 원래 데이터 세트의 sample과 시각적으로 유사한 보다 발전된 model hijacking을 제안한다.
모델 하이재킹 공격 수행하려면 대상 모델의 학습데이터를 중독시킬 수 있는 능력만 있으면 된다. 이는 모델 하이재킹이 연합학습과 같이 데이터 중독에 취약한 모든 설정에 적용할 수 있음을 나타낸다.
공격자는 대상 모델의 학습 데이터 세트(original dataset)를 자신의 hijacking task의 훈련 데이터 세트(hijacking dataset)로 오염시키기만 하면 model hijacking attack을 구현할 수 있다. 그러나 original dataset과 hijacking datasets가 모두 크게 다를 수 있기 때문에 이러한 시도는 쉽게 감지될 수 있다. 따라서, 성공적인 model hijacking을 위해 다음과 같은 요구 사항을 정의한다.
- Hijacked model을 원래 작업과 관련하여 original dataset(original sample)의 sample과 hijacking 작업과 관련하여 hijacking dataset(hijacking sample)의 sample을 예측할 때 두 경우 모두 우수한 성능을 달성해야 한다.
- 공격의 실행은 은밀해야 한다. 즉, target(hijacking) 모델을 poison(query)하는 데 사용되기 전에 hijacking dataset의 sample을 위장해야 한다.
이러한 요구 사항을 충족하기 위해서 본 논문의 저자들은 Chamleleon attack과 Adverse Chameleon attack이라는 두 가지 model hijacking attack을 제안한다. 또한 두 공격을 모두 구현하기 위해서 먼저 hijacking dataset의 sample을 더 은밀하게 위장하는 encoder-decoder based model인 Camouflager를 제안한다.

Camouflager Camouflager는 두 개의 encoder로 구성되어 있다.
첫 번째 encoder는 hijacking dataset의 sample을 encoding 한다. 두 번째 encoder는 공격자가 hijacking dataset와 시각적으로 유사하기를 원하는 dataset의 sample을 encoding 하며, 이 dataset을 hijackee dataset라고 부른다.
이때, 이상적으로는 hijackee dataset이 target dataset과 동일한 분포에서 나와야 한다.
그런 다음 두 encoder는 camouflaged(위장된) sample을 출력하는 decoder로 공급된다. 이러한 camouflaged samples는 시각적으로는 hijackee sample과 유사하지만 의미론적으로는 hijacking samples와 유사해야 한다.
Camouflager는 target model과 독립적이기 때문에 유사한 작업을 수행한 여러 대상 모델을 hijacking 할 때 사용할 수 있다.
이때 Camouflager는 viusal loss와 semantic loss를 기반으로 한다.
Visual Loss Camouflager's의 출력, 즉 camouflaged dataset을 hijackee dataset과 시각적으로 유사하게 만든다. Semantic Loss Camouflaged dataset을 hijacking dataset과 의미적으로 유사하게 만들어 hijacking task를 구현할 수 있도록 한다. Camouflager를 훈련시킨 후 공격자는 이를 사용하여 hijacking dataset을 위장하고, 출력 위장 데이터 세트를 사용하여 target model을 poison 할 수 있다.
마지막으로 공격을 시작하려면 공격자가 먼저 원하는 hijacking sample을 위장한 다음 위장된 sample을 hijacking model에 query 해야 한다. 결국 공격자는 예측된 label을 hijacking task와 관련된 label로 mapping 한다.
성공적인 model hijacking attack을 original dataset 또는 camouflaged dataset의 sample을 올바르게 예측해야지만, 즉, 먼저 camouflager에 의해 위장되지 않고 hijacking dataset의 sample은 무작위로(camouflaged sample의 성능보다 현저히 낮음) 예측해야 한다.
이와 같은 성공적인 model hijacking attack의 요구사항을 좀 더 공식적으로 나타내면 아래와 같다.
- 요구사항 1: Hijacked model은 original task에서 target model과 유사하거나 더 나은 성능을 가져야 한다.
- 요구사항 2: Hijacking dataset은 hijakee dataset으로 위장하여 공격을 더욱 은밀하게 해야 한다.
- 요구사항 3: Hijacked model은 hijacking task와 관련하여 camouflaged sample을 올바르게 분류해야 한다.
- 요구사항 4: Model hijacking attack은 은밀성을 더욱 높이기 위해 hijaked model은 hijaking dataset에서 임의의 non-camouflaged sample을 무작위로, 즉 camouflaged sample의 성능보다 현저히 낮은 분류를 해야 한다.
2.2 Model Hijacking v.s. Backdooring v.s. Data Poisoning
해당 섹션에서는 model hijacking attack을 data poisoning 및 backdooring이라는 기존 두 가지 training time attack과 비교하고 있다. 이때 해당 비교에서는 세 가지 방법모두 동일한 공격자 가정을 따른다. 그러나 model hijacking attack을 사용하면 공격자는 다른 목표를 갖게 된다고 한다.
우선, data poisoning attack에서 공격자가 target model의 훈련을 조작하여 model의 유용성을 떨어뜨리려 한다. 즉, 오분류율을 높이려고 하는 것이다. 마찬가지로 backdooringa attack 역시 동일한 목적을 가질 수 있며, 공격자는 트리거를 특정 model 출력과 연결할 수 있다. 예를 들어, 트리거가 임의의 입력에 삽입되면 target model은 공격자에 의해 미리 정의된 label을 예측한다. 이러한 트리거는 이미지 분류 모델의 입력 이미지의 모서리에 있는 흰색 사각형과 같은 것일 수 있다.
반면에 모델을 hijacking 하는 것은 모델 소유자에게 눈에 띄지 않고 원래 작업과 상관없이 다른 비윤리적인 작업을 구현하는 것이다. 예를 들어, 공격자는 포르노 영화에 대한 안면 인식 분류기 또는 sexuality 분류기를 구현하기 위해 모델을 hijacking 할 수 있며, 모델을 hijacking 하면 공격자가 자신의 모델을 유지하는 데 드는 비용을 절약할 수도 있다. 즉, 모델을 hijacking 하는 것은 공격자의 임무를 수행하기 위해 타인의 모델을 다른 용도로 사용하는 것이다. Backdooring attack은 model hijacking의 특정 사례로 볼 수 있는데, 여기서 공격자의 임무는 특정 label에 대한 트리거 된 입력을 예측하는 것이다.
그러나 공격자는 hijacking attack에서 target model의 원래 작업과 유사하거나 더 적은 수의 label을 사용해야 한다는 제한만 있을 뿐, hijacking 작업을 자유롭게 결정할 수 있다.
2.3 Building Blocks
Camouflager 2.3.1 Camouflager (AE_C)
Camouflager는 hijacking dataset D_h를 hijakee dataset D_o에 위장시키는 encoder-decoder 기반의 모델이다. 위 2.1에서 간단하게 설명하였듯이 camouflager는 두 개의 encoder로 구성되어 있다. 첫 번째 encoder(E_o)는 hijakee dataset의 sample(x_o)를 입력으로 받고, 다른 encoder(E_h)는 hijacking dataset sample(x_h)를 입력으로 받는다.
두 encdoer의 출력은 연결되어 decoder(E^(-1))의 입력으로 사용된다. Decoder는 x_0의 시각적 외관을 가지면서 x_h의 feature/semantrics를 가진 camouflaged sample x_c를 생성한다. 이를 수식으로 표현하면 아래와 같다:

여기서 x_o는 original dataset의 sample을 나타내며 (x_o∈ D_o), x_h는 hijacking dataset의 sample을 나타낸다. (x_h∈ D_h), x_c는 camouflaged sample이다.

Encoder Architecture 
Decoder Architecture 위 그림을 통해 확인할 수 있듯이 encoder와 decoder architecture는 simple한 구조임을 확인할 수 있다.
2.3.2 Visual Loss (φ_(vl))

위 수식에서 || . || 는 두 sample 간의 L1 distance를 나타낸다.
2.3.3 Semantic Loss
Semantic loss는 camouflager의 출력을 hijacking sample의 feature와 연결하는 loss이다. Semantic loss는 feature level에서 작동하므로, 먼저 주어진 sample의 feature를 추출하는 feature extractor F가 필요하다. 이 feature extractor는 어떤 classification model의 중간 layer일 수 있다. 이때, 공격자가 target model에 대한 어떠한 정보도 모른다는 가정을 따르기 때문에, 본 논문의 저자들은 pre-trained MoblieNetV2를 feature extractor로 사용하였다. 만약 더 강력한 공격자가 target model에 접근할 수 있다면 target model을 feature extractor로 사용할 수 있다. F의 어떤 layer의 출력도 fature로 사용할 수 있지만, 본 연구에서는 MobileNetV2의 끝에서 두 번째 layer의 출력을 사용하였다. Semantic loss는 camouflater의 출력과 hijacking sample의 feature 간의 L1 distance를 계산한다. 이를 수식으로 표현하면 아래와 같다:

2.3.4 Adverse Semantic Loss
Viusal and semantic loss는 camouflager의 출력을 hijackee sample의 시각적 외관과 hijacking sample의 feature와 연결한다. 그러나 hijacking dataset과 hijackee dataset이 복잡하고 유사한 경우, camouflaged sample의 featue가 hijackee sample의 feature와 충분히 구별되지 않아 model hijacking attack의 성능이 저하될 수 있다. 따라서 본 논문의 저자들은 또 다른 loss function 인 Adverse Semantic Loss를 도입하였다. 이 loss는 L1 distnace를 사용하여 hijackee sample과 camouflaged sample의 feature 간의 차이를 극대화한다. 이를 수식으로 표현하면 아래와 같다:

2.3 The Chameleon Attack
Chameleon attack은 Camouflager를 사용하여 hijacking dataset을 위장하고 target model을 poison 한다.
해당 공격 방법은 크게 준비, 위장, 실행 세 단계로 나눌 수 있다.
2.3.1 Preparatory (준비)
첫 번째 단계에서, 공격자는 hijacking datset과 hijackee dataset을 준비한다. hijakee dataset은 hijacking dataset을 위장하는 데 사용된다.
다음으로, hijakee dataset을 만든 후, 공격자는 원본 dataset의 label과 hijacking dataset의 label 간의 mapping을 만든다. Original dataset의 i-th label을 hijacking dataset의 i-th label에 할당하며, 해당 논문에서는 각 label의 의미는 고려하지는 않는다. 하지만 이 공격은 mapping 기술에 독립적이며, 공격자는 일관성을 유지하는 한 자유롭게 매핑을 생성할 수 있다. 즉, 어떤 mapping 방법이든 일관성만 유지하면 된다는 것이다.
마지막으로, 공격자는 Camouflager를 훈련시키기 위해 필요한 sample의 feature를 계산하는 데 사용될 feature extractor F를 선택한다. F는 일반적으로 사용할 수 있는 모델로, 공격자가 자유롭게 선택할 수 있다.
2.3.2 Camouflaging (위장)
Hijackee dataset, label mapping, and feature extractor를 결정한 후, 공격자는 이제 Chameleon (카멜레온) 공격의 주요 프로세스를 시작할 수 있다. 이 공격을 위해 visual and semantic loss를 모두 사용하여 Camouflager를 구축한다.
위에서 설명하였든 Camouflager는 두 개의 encoder와 하나의 deocder를 사용한다. 모두 두 가지 loss function과 함께 공동으로 훈련된다. 이를 수식으로 표현하면 아래와 같다:

위의 수식을 통해 확인할 수 있듯이, Camouflager는 target model과 독립적이다. 따라서 유사한 original task를 가진 여러 target model을 hijacking 하는 데 사용할 수 있다.
카멜레온 공격을 위해, 공격자는 hijackee dataset과 hijacking dataset을 사용하여 Camouflager를 훈련시킨다. 훈련 순서는 아래와 같다:
- 각 epoch 마다, 공격자는 먼저 hijackee과 hijacking dataset의 sample을 무작위로 짝지어 준다. 두 dataset의 크기기가 다를 수 있으므로, 두 dataset 간의 mapping은 일대일이 아닌 다대다일 수 있다. Camouflager의 generalizability를 높이기 위해 각 epoch마다 mapping을 변경한다.
- Sample을 mapping 한 후, 각 sample을 Camouflager에 입력한다. 마지막으로, Camouflager의 추려과 입력 sample을 사용하여 위의 loss function(1)을 통해 Camouflager를 업데이트한다.
2.3.3 Executing (실행)

An overview of the model hijacking attack. First, the adversary inputs the hijackee and hijacking datasets to the Camouflager. Next, they take the Camouflager’s output (the camouflaged dataset) and poison the training dataset of the target model. Finally, the model is trained with the poisoned dataset. Camouflager를 훈련한 후, 공격자는 이제 공격을 실행할 수 있다. 위 그림은 Camouflager 훈련 후 카멜레온 공격의 개요를 나타낸다. 그림에서 확인할 수 있듯이, 먼저 공격자는 hijackee dataset 내의 sample을 hijacking dataset의 sample과 mapping 하고, 훈련된 Camouflager를 query 하여 camouflaged dataset을 만든다. Camouflaged dataset을 만들 때 사용된 label을 target model의 학습을 오염시켜 hijacking 한다. Poisoned dataset을 사용하여 학습된 target model을 hijacked model이라고 부른다.
target model을 hijacking 한 후, 공격자는 먼저 Camouflager를 사용하여 hijacking dataset의 분포에서 sample을 위장한다. 그런 다음, camouflaged sample을 hijacking 된 model에 query 하고, 예측된 albel을 hijacking dataset의 대응 label로 mapping 한다.
2.4 The Adverse Chameleon Attack
이전 섹션에서 설명하였듯, Chameleon Attack은 hijacking dataset과 hijackee dataset이 상당히 다를 때 좋은 성능을 보인다. 그러나 두 dataset이 복잡하고 크게 다르지 않을 때는 성능이 저하된다. 따라서 본 논문의 저자들은 더 강화된 형태의 공격인 Adverse Chameleon Attack을 제안한다.
Adverse Chameleon Attack 은 Camouflager의 출력과 hijackee dataset의 feature map을 명시적으로 멀어지게 한다. 이를 위해 visual and semantic loss 외에도 Adverse Semantic Loss를 사용한다. 해당 loss를 추가한 Camouflager의 training loss function의 수식은 아래와 같다:

공격자는 adverse chameleon attack을 실행하기 위해서 chameleon attack과 동일한 단계를 따른다.
3. Experiment
3.1 Evaluation Metrics
3.1.1 Utility (유용성)
유용성은 하이재킹 된 모델의 성능이 원본 데이터셋에서 깨끗한(즉, 하이재킹되지 않은) 모델의 성능과 얼마나 가까운지를 측정한다. 하이재킹된 모델과 깨끗한 모델의 성능이 가까울수록 모델 하이재킹 공격이 더 좋다는 것을 의미한다.
구체적으로, 유용성을 측정하기 위해 하이재킹된 모델과 깨끗한 모델의 정확도를 깨끗한 테스트 데이터셋에서 비교하며, 여기서 테스트 데이터셋은 원본 데이터셋과 동일한 분포를 가진다.
3.1.2 Attack Success Rate (공격 성공률)
공격 성공률은 하이재킹된 모델의 하이재킹 데이터셋에서의 성능을 측정한다. 공격 성공률은 하이재킹된 모델이 하이재킹 테스트 데이터셋에서 보여주는 정확도를 계산하여 측정한다. 여기서 테스트 데이터셋은 하이재킹 데이터셋과 동일한 분포를 가지며, Chameleon 및 Adverse Chameleon 공격 모두에서, 우리는 하이재킹된 모델에 쿼리 하기 전에 하이재킹 테스트 데이터셋을 먼저 위장하고, 그 후 정확도를 계산한다.
3.2 The Chameleon Attack

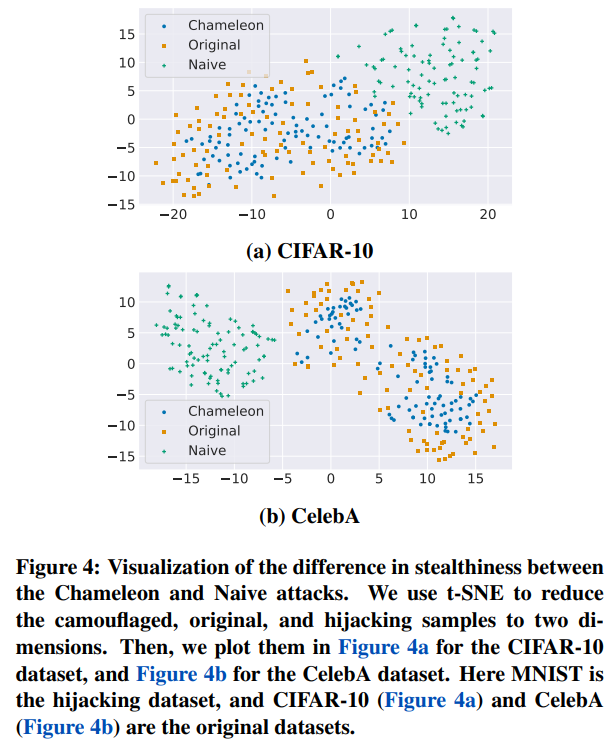

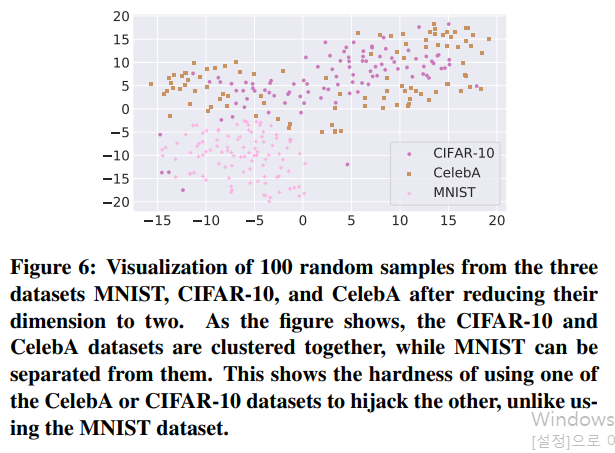
3.3 The Adverse Chameleon Attack



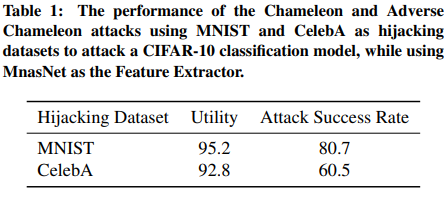
3.4 Different Target Models and Feature Extractor

'AI > Vision' 카테고리의 다른 글
3D Gaussian Splatting for Real-Time Radiance Field Rendering (0) 2024.11.25 Bayesian Optimization Meets Self-Distillation (0) 2024.08.09 DDPM: Denoising Diffusion Probabilistic Models (0) 2024.08.06 StyleSync: High-Fidelity Generalized and Personalized Lip Sync in Style-based Generator (0) 2024.05.08 Prototypical Contrastive Learning of Unsupervised Representation (1) 2024.02.05