-
Deblur-NeRF: Neural Radiance Fields from Blurry ImagesAI/Vision 2023. 5. 12. 18:29
CVPR 2022
Deblur-NeRF: Neural Radiance Fields from Blurry Images
Li Ma 1* Xiaoyu Li 2 Jing Liao 3 Qi Zhang 2 Xuan Wang 2
Jue Wang 2 Pedro V. Sander 1
doi : https://doi.org/10.48550/arXiv.2111.14292
Deblur-NeRF: Neural Radiance Fields from Blurry Images
Neural Radiance Field (NeRF) has gained considerable attention recently for 3D scene reconstruction and novel view synthesis due to its remarkable synthesis quality. However, image blurriness caused by defocus or motion, which often occurs when capturing s
arxiv.org
1. Introduction
최근 NeRF의 등장은 novel view synthesis에 있어서 현실적인 Rendering 결과를 달성하는 scene representation으로 등장하였다. 이는 3d scene을 resonsturction 하여 새로운 view를 만들고 quality를 높여 준다.
정적인 장면은 3d loaction 및 2d view direction to color and density를 mapping 하는 continous volumetric으로 model 화한다. 이 함수는 multilayer perceptron (MLP)으로 parametrized 할 수 있으며 그 output은 continous volumetric 기술로 rendering 될 수 있다.
이렇게 MLP로 구성된 NeRF는 잘 capture 된 이미지에서는 좋은 성능을 가진다. 그러나 blur가 발생하는 경우에는 artifacts가 남게 되는 문제가 있다.
예를 들어 low-light scene을 capture 하기 위해서 long exposure 설정을 사용하는 경우 이미지가 카메라의 흔들림에 더 민감해지게 되고 이로 인해 motion blur가 발생한다. 또한 large aperture를 사용하여 depth variation 큰 scene을 capture 할 때는 defocus blur가 불가피하게 생성되게 된다. 이러한 blur들은 reconstructed NeRF의 품질을 크게 감소시켜 rendering 된 novel view에 artifacts를 생성하게 된다.
최근의 연구에서는 abnormal input을 NeRF 학습동안 다루기 위해서 많은 방법이 제안되었다.
Method 설명 NeRF-W 조명 변화와 움직이는 물체가 있는 이미지 초점을 맞춘다. Mip-NeRF Input이 다른 scale에 걸쳐 있을 때 NeRF를 개선한다. SCNeRF Input의 왜곡을 고려한다. 위 표와 같은 연구들이 있지만 이들이 아는 한 아직까지 blurry image input을 고려한 NeRF는 존재하지 않는다고 한다.
그래서 이들은 blurry image input을 고려하기 위해 두 가지 방법을 고려하였다.
[ 1 : Input 으로 사용하기 전 먼저 deblur를 진행한 뒤 NeRF의 input으로 사용 ]
novel view synthesis quality를 높이기 위해 기존에는 이미지 공간에서 deblur를 진행하고 NeRF의 input으로 사용방식을 사용했다.
Image-space baseline이라고 불리며 이는 Single image 혹은 video deblurring methods로 NeRF의 novel view synthesis quality를 높이기 위한 방법이다.
하지만...
Single image deblur methods --> neighbor view에서 정보를 aggregate 하지 못하며 multi-view에서는 일관된 결과를 보장하기 어렵다는 문제가 있다.
Video deblurring methods --> 일반적으로 optical flow 및 feature correlation volume과 같은 이미지 공간 작업에 의존하여 multi-frame을 고려한다. 그러나 이러한 방법은 장면의 3d geometric scene을 활용하지 못하며 특히 큰 baseline 있을 때 view 간에 부정확한 대응관계를 초래한다.
[ 2: 본 논문에서 제안하는 방법 ]
본 논문에서는 network에서 blurring process를 명시적으로 모델링하고 blurry input으로부터 선명한(sharp) NeRF를 restoring 할 수 있는 효과적인 framework인 Deblur-NeRF를 제안한다.
Blind deconvlution과 유사한 blur kernel을 사용하여 깨끗한 이미지를 convolution 하여 blurring process를 모델링한다.
이 blur kernel을 모델링하기 위해 deformable sparse kernel(DSK) module을 제안한다.
DSK는 아래의 내용(관찰)에 영감을 받아 설계하였다고 한다.
1. 밀도가 높은 kernel을 사용한 convolution은 renderning 중 computation 및 memory 사용량의 급격한 증로 인해 NeRF와 같은 scene representation에 적합하지 않다. 이를 해결하기 위해서 DSK는 sparse rays를 사용하여 밀도가 높은 kernel을 근사화한다.
2. actual blurring process가 서로 다른 original rays를 결합하는 것을 포함하며, 이는 이들이 orignal rays를 공동으로 optimize 하는 것에 motivate가 되었다.
3. Spatial-varying kernel을 모델링하기 위해 각 2d spatial loaction에 canonical sparse kernel을 변형한다. 변형은 다양한 유형의 blur로 일반화할 수 있는 MLP로 parameterized 한다.
Training 중에 이들은 DSK와 sharp NeRF를 함께 supervision으로 blurry input만 사용하여 optimize 하고 inference stage에서는 DSK를 제거하여 명확한 novel view를 rendering 할 수 있다.
이들은 카메라 motion blur와 defocus blur라는 두 가지 유형의 blur를 사용하여 synthesis 및 real dataset에서 광범위한 실험을 진행하였다.
- blurry input에서 sharp NeRF를 recontruct 하는 framework를 최초로 제안한다.
- blurring process를 효과적으로 모델링할 수 있고 다양한 유형의 blur에 대해 일반화할 수 있는 deformable sparse kernel (DSK) module을 제안한다.
- Physical blurring process를 분석하고 각 kernel point에 대한 original rays의 변환을 고려하여 2d kernel을 3d 공간으로 확장한다.
2. Premliminary
우선 3d 장면에 대한 기존의 NeRF representation에 대해서 알아보자.
NeRF는 scene을 3d position x와 2d view direction d를 color c and volume density σ에 mapping 하는 continous volumetric function으로 정의한다.

continous volumetric function 여기서 FΘ 는 매개변수 Θ가 있는 MLP를 나타내며 γL(·) 은 vector의 각 element를 higher dimension frequency sapce로 mapping 하는 positional encoding이다.
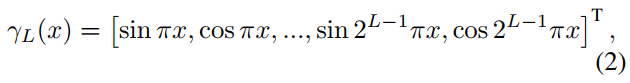
Positional encoding function 여기서 hyper-parameter L은 mapping에 사용된 highest frequency를 나타내며 scene function의 smoothness를 제어하는 데 사용할 수 있다.
이미지 좌표 p에 중심에 있는 pixel을 rendering 하기 위해 먼저 camera projection center o에서 viewing direction d_p를 따라 ray r_p(t) = o + td_p를 방출한다.
그런 다음 sampling strategy를 사용하여 미리 정의된 가까운 평면과 먼 평면 t^(0) and t^(D+1) 사이의 sorted sitances인 D를 {t^(i)}(^D)(_i=1)를 결정한다. FΘ를 사용하여 각 sample point r_p(t^(i))를 색상 c^(i) 및 density σ^(i)를 추정한다.
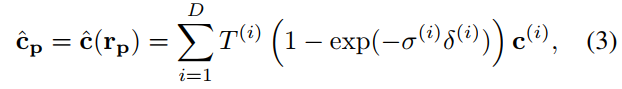
여기서 δ(i) = t(i+1) − t(i) 은 인접한 sample 사이의 거리이고
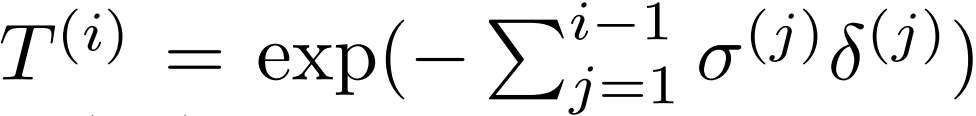
이다.
4. Method

Deblur-NeRF Goal : train the NeRF with blurry input
Core : blurring process를 명시적으로 모델링하고 sharp NeRF와 the blur parameters를 공동으로 최적화하여 synthesized blurry image와 Input에 일치하도록 하는 것.
* 명시적 모델(Explicit Model)? 확률 분포의 모양에 대한 가정이 분명히 드러나고 이 확률 분포에 대한 파라미터가 명확하게 드러나는 것이 특징인 모델 *
훈련 중에 blurry pixel을 rendering 하기 위해서 먼저 blurring process를 모방하는 DSK module을 이용해서 최적화된 여러 ray를 생성한다. NeRF를 이용하여 이러한 ray를 rendering 하고 결과를 혼합하여 최족적으로 blurry color를 얻은 다음 blurry input에 의해 supervised 된다.
Inference : SDK를 제거하고 NeRF를 직접 rendering 하여 clear novel views를 얻는다.
4.1 Deformable Sparse Kernel
대부분의 이미지 deblurring process의 algorithms과 유사하게 sharp image를 blur kernel h로 convolution 하여 blurring process를 모델링한다.

여기서 c_p는 sharp pixel p의 색상이 이며 이상적인 sharp NeRF에서의 output이다.
b_p는 blurry colder이며 * 는 convolution operator이다. blur kernel은 일반적으로 p를 중심으로 하는 K x K window를 정의한다. b_p를 계산하기 위해 창 내부에서 c_p와 h의 요소별 곱을 취한다. 이는 map-based image representation에서 효율적으로 계산할 수 있다.
그러나 c_p가 NeRF로 모델링 될 때 rendering이 상당한 computation 및 memory가 소요되기 때문에 문제가 발생한다. 각 pixel에 대해 supporting window에서 rendering 해야 하는 K x K의 ray가 생성되기 때문에 training을 수행할 수 없어진다.
그래서 이들은 적은 수의 sparse point로 dense blur kernel을 근사하는 방법을 제안하였다.

N(p) : sparse kernel의 support를 구성하는 p 주변에 sparsely 하게 분포된 N의 집합.
w_q : 각 위치에서의 해당 weight
N은 고정된 숫자로 설정한다. q는 연속 값이며 위치 N(p), w_q 및 NeRF를 공동으로 최적화하여 best sparse kernel이 regressed 하도록 할 수 있다.
일반적으로 real world image에서 blur kernel은 공간적으로 다양하다.
Continuous 5D function을 MLP로 사용하는 NeRF에 영감을 받아 spatially-warning kernel을 MLP로 모델링하였다.
Input view에 대해 "canonical kernel locations"

canonical kernel locations 를 할당하고 MLP를 사용하여 위치를 번형 하며 weight를 예측한다.

G_Φ : 매개변수 Φ가 있는 MLP
l : learned view embedding. blur pattern은 일반적으로 view마다 다르기 때문에 이 view embedding이 필요하다.
각 view에 대해 서로 다른 view embedding을 최적화하면 DSK module이 각 view에 대해 서로 다른 blur kernel을 맞출 수 있다. 아래의 수식으로 N(p)에서 최종 sparse kernel location을 계산한다.

모든 deformed location을 얻으려면 MLP를 N번 forward 해야 한다.
잠재적으로 성능을 향상할 수 있는 옵션은 위의 식(6)의 입력 P를 γ(p)로 대체하여 G_Φ에 위치 인코딩을 도입하는 것이다. 그러나 이러한 방법은 공간적으로 변화하는 kernel이 high-frequency 변화 없이 공간적 위치에 따라서 변화하기 때문에 operation의 quality 향상에 도움이 되지 않는다.
4.2 Convolution with Irradiance
Blur convolution은 model의 image intensity 대신 scene irradiance에 적용을 해야 한다. 이때 보다 물리적으로 올바른 모델은 다음과 같은 수식을 따른다.

이때 c'. 은 scene irradiance이며 f()는 cmaera reponse function(CRF)로 scene irradiance를 image intensity에 mapping 하는 함수이다.
Non-linear CRF는 특히 high contrast regions에서 blur kernel의 complexity를 증가시키고 위의 blurring process과 같은 선형모델을 사용하면 DSK의 학습이 어려워진다. 그러므로 저자들은 Non-linear CRF를 보완하기 위해 아래의 수식(7)과 같이 Sharp NeRF가 linear space에서 색상을 예측하고 최종 출력에 simple gamma correction function을 채택한다.

g(c') = c'^(1/2x2)이다. 더 복잡한 CRF를 사용하여 real world camera를 사용하거나 훈련 중에 CRF를 공동으로 optimziing 할 수도 있지만 이 간단 하만 방식만으로도 imageing process의 non-linearity를 보정하고 quality를 개선하기에 충분하다고 한다.
4.3 Optimizing the Ray Original
Convolution model에서 blurry result는 camera center가 원점과 동일한 이웃 ray의 렌더링 결과인 이웃 pixel의 조합이기 때문에 convolution model은 actual blur model의 2d 근사치라고 한다.

하지만 actual blurring process에서는 일반적으로 서로 다른 원점에서 투사된 ray를 blending 한다.
위 그림과 같이 2가지 blurring process를 생각해 보자
camera motion blur capture --> 한 번의 촬영 중에 camera의 중심이 움직이면 camera의 원점이 변경된다.
defocus blur capture --> ray가 다른 방향으로 흩어지게 되는데, 이는 서로 다른 원점의 ray가 혼합된 것과 같다.
scene이 대부분 평면인 경우 ray 원점의 이동은 pixel 위치의 2d 이동으로 잘 근사화할 수 있다. 그러나 parallex effect와 occlusion으로 인해 depth discontinuity가 있는 경우에는 그렇지 않다.
이때 우리는 3D scene에 access 할 수 있기 때문에 ray 원점의 변화를 고려한 kernel을 개발할 수 있다. 따라서 각 sparse kernel 위치의 ray 원점이동을 공동으로 optimize 한다. 이는 아래의 식 (6)과 같이 각 kernel 위치에 대한 원점 이동을 공동으로 예측한다고 한다.

그리고 이 rays를 다음 수식과 같이 생성한다.

이렇게 최적화된 ray를 rendering 하고 결합하여 최종 blurry pixels를 얻는다.
Training process는 다음과 같이 정리할 수 있다.
1. 식(8)을 이용해서 튜플을 예측한다.
2. 이를 바탕으로 식 (9)에서와 같이 표준 샘플링 위치를 변형하고 ray 원점을 optimize 하여 여러 개의 optiming 된 ray를 생성한다.
3. 이 ray를 redering 하여 식(3)을 사용해 c'_q를 얻고 식(7)을 사용하여 blend 하여 blurry pixel b^p를 얻는다.
4. 이 synthetic blurry pixel은 ground truth pixel color b_gt에 의해서 supervised 학습된다.

R : The set of pixels in each batch
해당 pipeline은 위에서 언급하였듯 training에만 사용된다.
test 시에는 gamma correction을 통해 복원된 sharp NeRF를 사용하여 sharp result를 직접 rendering 할 수 있다.
4.4 Aligning the NeRF
학습 가능한 모든 구성 요소, 즉 NeRF와 deformable sparse kernel을 자유롭게 optimize 하면 reconstructed 된 NeRF는 약간의 non-rigid distortion을 겪을 수 있다. 이는 이들의 예상과 일치하는 것으로, recontructed blurry result에 영향을 미치치 않고 NeRF로 학습된 kernel로 표현된 scene이 함께 변형될 수 있기 때문이다. 그러나 이는 일반적으로 바람직하지 않은 것이라고 한다. 그러므로 NeRF model이 관측치와 일치하도록 제한해야 한다고 한다.
NeRF model이 관측치와 일치하도록 제한하기 위해서 모든 optimized rays r_q가 input ray r_p에 근접하도록 deformable sparse kernel을 initialize 해야 한다. 이는 output tuples (∆oq, ∆q, wq)에 gain ϵ = 0.1을 곱하여 구현된다.
결과적으로, ray 원점 o_q와 kernel point q는 각각 카메라 중심과 pixel 위치에 가깝게 초기화된다. 그리고 모든 kernel point는 training을 시작할 때 거의 동일한 가중치를 가진다. 또한 optimize 된 ray r_q 중 하나가 input ray r_p와 유사하도록 하는 아래 수식과 같은 alignment loss를 적용한다.

alignment loss q_0 : fixed element in N(q)
L_aglign의 적용을 통해 이들은 q_0의 kernel이 중심이 되도록 supervised 한다. 이들은 실험을 통해 위 수식에서 λ_o=10으로 설정하였다.
NeRF reconstructure loss와 alignment loss를 조합한 최종적인 loss는 아래의 수식과 같이 나온다.

이때 실험을 통해 저자들은 λ_a=0.1로 설정하였다.
5. Experiment





정리
Deformable sparse kernel을 end-to-end로 blur scene을 생성하며 NeRF를 학습하고 test시에 blurry process를 제외하고 NeRF만 사용하여 deblur 된 scene을 만들 수 있다는 것이 좋은 방법이라 생각이 들었다. NeRF 뿐만 아니라 다양한 degradation을 피하고 좋은 성능을 얻기 위한 문제를 해결하기 위해 많은 연구가 이루어지는데 이 방법을 여기서 이용해도 좋은 성능을 얻을 수 있을 것이라 생각이 들었다.
'AI > Vision' 카테고리의 다른 글