-
3D Dental Mesh Segmentation Using Semantics-Based Feature Learning with Graph-TransformerAI/Bio & Medical 2023. 11. 10. 12:12
MICCAI 2023
3D Dental Mesh Segmentation Using
Semantics-Based Feature Learning with Graph-Transformer
Doi: https://doi.org/10.1007/978-3-031-43990-2_43
0. Background
본 논문을 읽기 전에 mesh가 무엇인지 알고 넘어가 보자!
< Mesh? >
Mesh는 3차원 물체를 정의하는 vertices, edges, faces의 list이다.
즉, 폴리곤들이 모인 하나의 차원 물체를 의미한다.
- vertices: 3d 공간상의 좌표
- Edges: 각 vertex를 연결하는 선
- Faces: 각 선들을 3개 이상 연결하여 만들어진 면

출처: https://ko.wikipedia.org/wiki/%ED%8F%B4%EB%A6%AC%EA%B3%A4_%EB%A9%94%EC%8B%9C 간단하고 빠르게 만들기 위해서 보통 삼각형을 사용하여 제작한다.
Mesh는 코드로 정의하기 쉽다는 장점이 있다.
Mesh를 저장할 시에 edges 만 메모리에 저장한다. 선분들과 면들은 정점들의 순서로 요약해서 정의된다.
1. Introduction
3D Dental Mesh Segmentation: 별개의 구성요소, 즉 개별의 치아와 잇몸으로 정확히 구분하는 것을 목표로 한다.
안정적이고 정확한 3d dental mesh segmentation 은 치아 교정 및 의치 디자인을 포함한 다양한 oral medicine 영역에서 필수적인 역할을 하며, 후속 절치 및 치료에도 중요하다.
그러나 기존 3d dental mesh segmentation 은 아래와 같은 문제점을 가지고 있다.
- Scan 정확도의 본질적인 한계: mesh로 scan 될 때 정확도의 한계가 존재한다.
- Reconstructed 3d dental mesh 내 상당한 noise 가 존재: 치아 경계가 흐려지는 문제가 발생하게 된다.

https://arxiv.org/abs/2012.13697 https://www.researchgate.net/figure/Digital-solid-dental-model-Figure-2-Mesh_fig1_334904688 그럼 기존 방법들에 대해서 살펴보도록 하자.
기존 방법은 크게 handcrafted method와 deep learning based method 가 있다.
< Method -1 >
일반적으로 좌표 및 법선 벡터와 같은 기하학적 속성을 활용하여 threshold segmentation을 수행한다.
이는 사전에 정의된 속성을 사용하기 때문에 자동화된 segmentation에서는 고품질의 결과를 얻기 어렵다는 단점이 있다.

출처: https://www.sciencedirect.com/science/article/pii/S001048251400287X < Method -2 (Deep Learning-based methods) >
위 method-1의 문제점 해결을 위해서 deep learning-based methods들이 연구되기 시작했다.
Deep learning-based methods에 대한 방법들 중 3가지만 확인해 보자.
1) Point-wise feature를 CNN과 같은 network에 공급하는 2d image처럼 압출하여 사용하는 방식
해당 방법은 mesho 고유의 topology를 무시하는 경향이 있어 segmentation quality가 좋지 않다는 단점이 있다.
※ 이때 mesh의 topology는 geometric surface characteristics of mesh를 의미한다. ※

출처: https://ieeexplore.ieee.org/document/8743393 
출처: https://link.springer.com/chapter/10.1007/978-3-030-32226-7_93 2) Tooth centroid extraction과 tooth segmentation으로 구성된 two-stage network 사용
해당 방법은 실제 scenes에서 흔히 볼 수 있는 과밀하거나 누락된 치아의 경우 동일한 성능을 기대할 수 없으며 추가 연산이 필요한 centroid label을 필요로 한 다는 단점을 가지고 있다.

출처: https://www.sciencedirect.com/science/article/pii/S1361841520303133 3) TSGCNet
C-steam (coordinate)와 N-stream (normal vector)의 feature를 별도로 추출하고 두 stream의 concatenated features에 따라 cell/vertex-wise segmentation결과를 예측하기 위해 two-stream graph convolution-based feature extraction network를 설계하였다.
해당 방법은 초기특징을 C-stream과 N-stream으로 분리하는 새로운 dental mesh feature process paradigm을 개척하였으며, feature를 update 할 때 topological continuity를 고려하기 위해서 graph convolutino이 사용되었다.
이 방식은 아래와 같은 문제점을 가진다.
- 빽빽한 치아의 경우 치아 경계에 여전히 약간의 어려움이 있다.
- 종속성을 modeling 하기 위해 graph convolution을 사용하기 때문에 어금니에서 종종 충돌이 발생한다.
- 기존의 방법은 항상 서로 다른 각도에서 형상을 직접 연결하여 정렬되지 않은 치아에 대한 잘못된 분할을 초래한다.

출처: https://doi.org/10.48550/arXiv.2012.13697 이렇듯 deep learning-based methods 가 많이 연구되었지만 품질은 여전히 임상 요구사항에 미치지 못한다.
그 이유는 아래의 세 가지 문제점 때문이다.
- Tooth morphology (치아 형태)의 복잡성
- Gingival line (치은선)의 모호함
- 일반적으로 중요한 insight를 제공하고 local geometric attributes를 향상할 수 있는 mesh cells의 semantic information을 무시하며 학습
본 논문의 저자들은 이러한 문제점을 개선하기 위해 아래와 같은 방법을 제안한다.
- 잘 설계된 graph transformer를 통해 semantic information을 최대한 활용하여 local 및 global 종속성을 보다 정확히 파악하고 mesh feature를 향상할 수 있는 새로운 semantic-based feature learning을 제안.
- Semantic 정보를 더욱 활용하기 위해 C-domain과 N-domain에서 gloabl 종속성을 흭득하고 domain 간 fature를 adaptively fuse 하는 새로운 feature fusion module 제안.
2. Proposed

위 그림은 본 저자들이 제안하는 framework이다.
우선 TSGCNet에 따라 spatial and geometric features를 각각 C-domain and N-domain을 초기 cross-domain features로 가져온다.
2.1 Semantics-based Graph-Transformer
Cross-domain features는 두 개의 N x 12 matrices로 가져오지만 대신 N-domain feature가 embedding domain 역할을 한다.

초기 feature vector를 N x 24 matrix로 나타내고, N은 cell 수를 나타내며,
24-dimensional vector는 12-dimensional relative coordinates(위 그림에서 주황색, C-domain) and 12-dimensional normal vectors(위 그림에서 파란색, N-domain)로 구성되어 있다.
그다음 dental mesh의 위치와 방향이 다양할 수 있기 때문에 Spatial Transformer Network (STN) module을 통해 C-domain과 N-domain을 불변하게 만든다.


Spatial position and geometric features를 각각 나타내는 Nx12 matrices의 two-domain으로 구성한 후, N-domain feature가 포함된 C-domain에 대해 semantic prediction을 수행하여 각 cell에 대한 pesudo semantic label L={l_1, l_2,..., l_n}을 생성한다.
그런 다음 semantic information에 따라 각 cell에 의미적 차이가 가장 적은 local 이웃에게 각 cell에 대해 graph transformer를 사용하고 다른 label을 가진 cell 간의 차이를 더 크게 만들기 위해 해당 feature를 update 한다.
N-domain의 경우 geometric sense에서 semantic label을 분류하고 local feature를 향상하는 데 도움이 될 수 있으므로 다른 수정 없이 주로 C-domain의 다양한 scale에 adapt 하도록 up-sampling 한다.
< Spatial Transformer Network (STN)?? >

STN 출처: https://tutorials.pytorch.kr/intermediate/spatial_transformer_tutorial.html STN은 어떠한 공간적 변경(spatial transformation)에도 적용할 수 있는 미분 가능한 attention의 일반화이다.
따라서 STN은 신경망의 기하학적 불변성을 강화하기 위해 입력 이미지를 대상으로 어떠한 공간적 변형을 수행해야 하는지 학습하도록 한다.
예를 들어 이미지의 관심 영역을 잘라내거나, 크기를 조정하거나, 방향을 수정할 수 있다.
이때 CNN은 이러한 회전, 크기 조정 등의 일반적인 affine 변환된 입력에 대해 결과의 변동이 크기 때문에, STN은 이를 극복하는데 매우 유용한 메커니즘이 될 수 있다.
STN이 가진 장점은 아주 작은 수정만으로 기존에 사용하던 CNN에 연결시킬 수 있다는 것이다.
< Semantics Prediction >

Semantics Prediction 의 official code Semantic information을 효과적으로 추출할 수 있는 각 cell에 대한 pseudo semantic label을 생상 하는 데 사용된다.
-> C-domain feature as C that has a shape of (N x k)로 정의
-> N-domain feature as N that has a shape of (N x k) 로 정의
Domain fusion의 weight를 나타내는 C-domain weight와 N-domain weight를 regress 한다.
따라서 cross-domain features F adaptively fused는 아래의 수식과 같다:
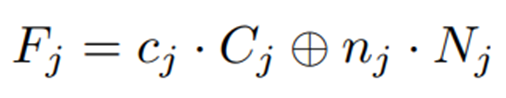
cross-domain features F adaptively fused j -> layer of the semantics-based Graph-Transformer module
c_j, n_j -> layer j의 C-domain과 N-domain의 adaptive weights, C_j, N_j는 이전 layer output
마지막으로 MLP를 수행하여 최종 pesudo semantic cell-wise label을 생성한다.
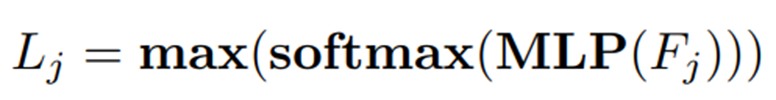
< Graph Transformer >

Graph Transformer의 official code Semantic KNN과 transformer encoder block으로 구성된다.
input C-domain에 대해 아래의 수식과 같이 형성된 semantic biased Euclidean distance를 기반으로 KNN graph를 구성한다.

semantic biased Euclidean distance 
Pseudo label 이 같으면 0을 주고 아니면 λ를 준다.
이를 통해 label이 같은 것은 distance가 가까워지고 아닌 것은 멀어지게 될 것이다.
그 후 transformer encoder block을 수행하여 local feature를 향상할 수 있는 local depencies를 얻을 수 있다.
Mlti-head attention(Q: matrices of neighbour features of the cells, K: distance matrix between cells and their neighbours)을 사용하여 연산을 진행한다.
2.2 Adaptive Cross-Domain Feature Fusion

Adaptive Cross-Domain Feature Fusion의 official code Cell-wise segmentation을 위해 C-domain과 N-domain features를 융합하는 것을 목표로 한다.
Semantics-based Graph-Transformer module을 통해 N-domain feature에 포함된 정확한 multi-scale C-domain feature를 얻었다. 이제 features를 융합하여 spatial information과 cell의 geometric information을 통합해야 한다.

Adaptive Cross-Domain Feature Fusion 따라서 먼저 서로 다른 규모의 특성에 대한 concatenate를 수행하고 MLP를 사용해 multi-scale feature를 융합하여 서로 다른 scale의 feature의 균형을 맞출 수 있다.

그 후 global graph transformer block을 통해 각각 C-domain과 N-domain에 standard multi-head attention을 사용하여 long distance dependencies를 포착하고 semantic information에 대한 global knowledge를 갖는다.
Learnable weight는 cross-domain feature를 adaptively 하게 융합할 수 있으므로 semantic prediction module에서 사용한 것과 유사한 cross-domain feature fusion 전략을 사용한다.
마지막으로 단인 MLP를 사용해서 feature mask를 생성하고 feature와 mask에 dot product를 수행한다.

3. Experiments



'AI > Bio & Medical' 카테고리의 다른 글